置顶通知
由于评论从畅言云评迁移到waline,导致评论数据丢失。非本人删除,各位大佬见谅!!!
由于评论从畅言云评迁移到waline,导致评论数据丢失。非本人删除,各位大佬见谅!!!
flowchart LR
subgraph calcite
A[1.SQL] -->|Parser| B[2.SQL Node]
B -->|Validator| C[3.SQL Node]
C -->|Convertor| D[4.Rel Node]
D -->|Optimizer| E[5.Rel Node]
end
E --> F[6.Physical Excute Plan]本文主要介绍Calcite 中的AST转执行计划。
flowchart LR
subgraph calcite
A[1.SQL] -->|Parser| B[2.SQL Node]
B -->|Validator| C[3.SQL Node]
C -->|Convertor| D[4.Rel Node]
D -->|Optimizer| E[5.Rel Node]
end
E --> F[6.Physical Excute Plan]本文主要介绍Calcite 中的SQL Validator。Calcite 通过 SQL 校验器实现 SQL 绑定,SQL 校验器所需的 Catalog 信息,在深入理解 Apache Calcite Catalog 中已经做了详细的介绍。
SQL 绑定主要的作用是将 SQL 解析生成的 AST 和数据库的元数据进行绑定,从而生成具有语义的 AST。SQL 绑定会通过自底向上的方式遍历 AST,对抽象语法树中的节点进行绑定分析,绑定的过程中会将表、列等元数据附在语法树上,最后生成具有语义的语法树 Bounded AST。
计算机科学中的随机数分为两种:
flowchart LR
subgraph calcite
A[1.SQL] -->|Parser| B[2.SQL Node]
B -->|Validator| C[3.SQL Node]
C -->|Convertor| D[4.Rel Node]
D -->|Optimizer| E[5.Rel Node]
end
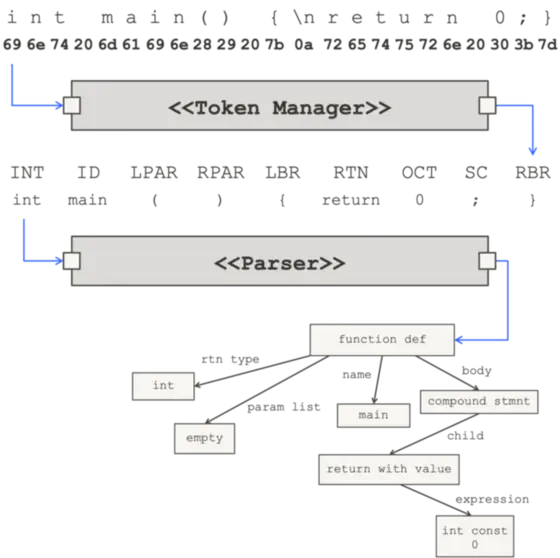
E --> F[6.Physical Excute Plan]Calcite 中的SQL Parser 使用JavaCC 实现。JavaCC 在前面的博客中有过介绍, 本文就不赘述了。本文主要介绍Parser。
上一篇文章我们简单介绍了 JavaCC的语法和使用。本文将以实现一个计算器为例,介绍JavaCC 在实际代码中的使用。
JavaCC 是 java 生态中常用的Parser Generator。特征如下:
JavaCC的工作流程如下:
假设我有两个 github 账号,victor(for personal) 和 superman(for work)。如果我想在同一台电脑上使用这两个账号进行 git push/pull。该如何配置?
如何在 Rust 的多线程中共享值?
ArcMutexPin 和 Unpin 标记 trait 搭配使用。固定保证了实现了 !Unpin trait 的对象不会被移动。先用一个简单点的例子来理解固定。