Git Worktree 并行开发
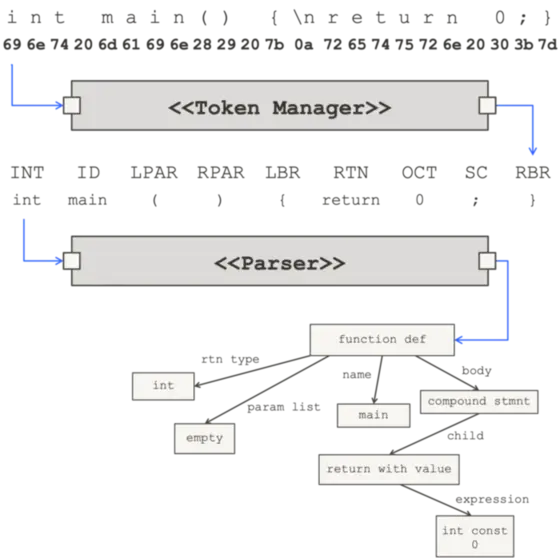
git worktree 命令支持管理同一个 git 仓库的多个工作区1,每个工作区可检出不同分支/提交。每个工作区都像一个“轻量级的独立仓库”,但它们共享底层对象库,减少磁盘占用并加速切换。
同一分支在同一时刻只能在一个 worktree 中被检出。如果想在多个 worktree 同时基于同一分支进行试验,需要使用不同分支名,或者使用--detach直接检出到某个提交。
注意,
--detach会产生分离式 HEAD,后续的修改会丢失,一般不推荐使用,除非是仅看用于查看代码。