What Every Programmer Should Know About Memory (2)
本文翻译自 What Every Programmer Should Know About Memory的第4,5章
虚拟内存
处理器的虚拟内存子系统为每个进程实现了虚拟地址空间。这让每个进程认为它在系统中是独立的。虚拟内存的优点列表别的地方描述的非常详细,所以这里就不重复了。本节集中在虚拟内存的实际的实现细节,和相关的成本。
虚拟地址空间是由CPU的内存管理单元(MMU)实现的。OS必须填充页表数据结构,但大多数CPU自己做了剩下的工作。这事实上是一个相当复杂的机制;最好的理解它的方法是引入数据结构来描述虚拟地址空间。
由MMU进行地址翻译的输入地址是虚拟地址。通常对它的值很少有限制。 虚拟地址在32位系统中是32位的数值,在64位系统中是64位的数值。在一些系统,例如x86和x86-64,使用的地址实际上包含了另一个层次的间接寻址:这些结构使用分段,这些分段只是简单的给每个逻辑地址加上位移。我们可以忽略这一部分的地址产生,它不重要,不是程序员非常关心的内存处理性能方面的东西[1]。
最简单的地址转换
有趣的地方在于由虚拟地址到物理地址的转换。MMU可以在逐页的基础上重新映射地址。就像地址缓存排列的时候,虚拟地址被分割为不同的部分。这些部分被用来做多个表的索引,而这些表是被用来创建最终物理地址用的。最简单的模型是只有一级表。
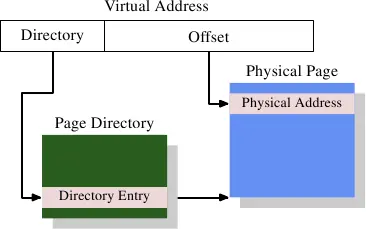
图 4.1 显示了虚拟地址的不同部分是如何使用的。高字节部分是用来选择一个页目录的条目;那个目录中的每个地址可以被OS分别设置。页目录条目决定了物理内存页的地址;页面中可以有不止一个条目指向同样的物理地址。完整的内存物理地址是由页目录获得的页地址和虚拟地址低字节部分合并起来决定的。页目录条目还包含一些附加的页面信息,如访问权限。
页目录的数据结构存储在内存中。OS必须分配连续的物理内存,并将这个地址范围的基地址存入一个特殊的寄存器。然后虚拟地址的适当的位被用来作为页目录的索引,这个页目录事实上是目录条目的列表。
作为一个具体的例子,这是 x86机器4MB分页设计。虚拟地址的位移部分是22位大小,足以定位一个4M页内的每一个字节。虚拟地址中剩下的10位指定页目录中1024个条目的一个。每个条目包括一个10位的4M页内的基地址,它与位移结合起来形成了一个完整的32位地址。
多级页表
4MB的页不是规范,它们会浪费很多内存,因为OS需要执行的许多操作需要内存页的队列。对于4kB的页(32位机器的规范,甚至通常是64位机器的规范),虚拟地址的位移部分只有12位大小。这留下了20位作为页目录的指针。具有 个条目的表是不实际的。即使每个条目只要4比特,这个表也要4MB大小。由于每个进程可能具有其唯一的页目录,因为这些页目录许多系统中物理内存被绑定起来。
解决办法是用多级页表。然后这些就能表示一个稀疏的大的页目录,目录中一些实际不用的区域不需要分配内存。因此这种表示更紧凑,使它可能为内存中的很多进程使用页表而并不太影响性能。.
今天最复杂的页表结构由四级构成。图4.2显示了这样一个实现的原理图。
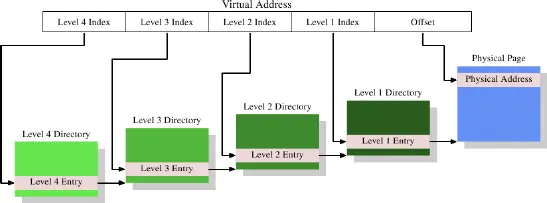
在这个例子中,虚拟地址被至少分为五个部分。其中四个部分是不同的目录的索引。被引用的第4级目录使用CPU中一个特殊目的的寄存器。第4级到第2级目录的内容是对次低一级目录的引用。如果一个目录条目标识为空,显然就是不需要指向任何低一级的目录。这样页表树就能稀疏和紧凑。正如图4.1,第1级目录的条目是一部分物理地址,加上像访问权限的辅助数据。
为了决定相对于虚拟地址的物理地址,处理器先决定最高级目录的地址。这个地址一般保存在一个寄存器。然后CPU取出虚拟地址中相对于这个目录的索引部分,并用那个索引选择合适的条目。这个条目是下一级目录的地址,它由虚拟地址的下一部分索引。处理器继续直到它到达第1级目录,那里那个目录条目的值就是物理地址的高字节部分。物理地址在加上虚拟地址中的页面位移之后就完整了。这个过程称为页面树遍历。一些处理器(像x86和x86-64)在硬件中执行这个操作,其他的需要OS的协助。
系统中运行的每个进程可能需要自己的页表树。部分地共享树是可能的,但不如说这是个例外状况。因此如果页表树需要的内存尽可能小的话将对性能与可扩展性有利。理想的情况是将使用的内存紧靠着放在虚拟地址空间;但实际使用的物理地址不影响。一个小程序可能只需要第2,3,4级的一个目录和少许第1级目录就能应付过去。在一个采用4kB页面和每个目录512条目的x86-64机器上,这允许用4级目录对2MB定位(每一级一个)。1GB连续的内存可以被第2到第4级的一个目录和第1级的512个目录定位。
但是,假设所有内存可以被连续分配是太简单了。为了弹性起见,大多数情况下,一个进程的栈与堆的区域是被分配在地址空间中非常相反的两端。这样使得任一个区域可以根据需要尽可能的增长。这意味着最有可能需要两个第2级目录和相应的更多的低一级的目录。
但即使如此也不总是符合当前的实际状况。为了安全考量,一个可执行程序的多个部分(程序码、资料、堆积、堆叠、动态共享物件〔Dynamic Shared Object,DSO〕,又称共享函式库〔shared library〕)会被映射在随机化的地址上 9。随机化扩大了不同部份的相对位置;这意味着,在一个进程里使用中的不同memory区域会广泛地散布在虚拟定址空间中。通过对随机的地址位数采用一些限定,范围可以被限制,但在大多情况下会让一个进程无法以仅仅一或两个第二与第三层目录来执行。
如果性能真的远比安全重要,随机化可以被关闭。操作系统通常至少会在虚拟memory中连续地载入所有的 DSO。
优化页表访问
页表的所有数据结构都保存在主存中;在那里OS建造和更新这些表。当一个进程创建或者一个页表变化,CPU将被通知。页表被用来解决每个虚拟地址到物理地址的转换,用上面描述的页表遍历方式。更多有关于此:至少每一级有一个目录被用于处理虚拟地址的过程。这需要至多四次内存访问(对一个运行中的进程的单次访问来说),这很慢。。将这些目录表的项目视为普通的资料、并在 L1d、L2、等等cache它们是办得到的,但这可能还是太慢了。
从虚拟内存的早期阶段开始,CPU的设计者采用了一种不同的优化。简单的计算显示,只有将目录表条目保存在L1d和更高级的缓存,才会导致可怕的性能问题。每个绝对地址的计算,都需要相对于页表深度的大量的L1d访问。这些访问不能并行,因为它们依赖于前面查询的结果。在一个四级页表的机器上,这种单线性将至少需要12次循环。再加上L1d的非命中的可能性,结果是指令流水线无法隐藏任何东西。额外的L1d访问也消耗了珍贵的缓存带宽。
所以,不只是将目录表的项目cache起来,而是连实体分页地址的完整计算结果也会被cache。因为同样的原因,代码和数据缓存也工作起来,这样的地址计算结果的缓存是高效的。由于虚拟地址的页面位移部分在物理页地址的计算中不起任何作用,只有虚拟地址的剩余部分被用作缓存的标签。根据页面大小这意味着成百上千的指令或数据对象共享同一个标签,因此也共享同一个物理地址前缀。
保存计算数值的缓存叫做旁路转换缓存(Translation Look-Aside Buffer,TLB)。因为它必须非常的快,通常这是一个小的缓存。现代CPU像其它缓存一样,提供了多级TLB缓存;越高级的缓存越大越慢。小容量的L1级TLB通常被用来做全关联式缓存,采用LRU回收策略。近来,这种cache的大小已经持续成长,并且渐渐被转变为集合关联式。因此,当一个新的项目必须被加入时,被逐出并取代的项目可能不是最旧的一个。
正如上面提到的,用来访问TLB的标签是虚拟地址的一个部分。如果标签在缓存中有匹配,最终的物理地址将被计算出来,通过将来自虚拟地址的页面位移地址加到缓存值的方式。这是一个非常快的过程;也必须这样,因为每条使用绝对地址的指令都需要物理地址,还有在一些情况下,因为使用物理地址作为关键字的L2查找。如果TLB查询未命中,处理器就必须执行一次页表遍历;这可能代价非常大。
通过软件或硬件预取代码或数据,会在地址位于另一页面时,暗中预取TLB的条目。硬件预取不可能允许这样,因为硬件会初始化非法的页面表遍历。因此程序员不能依赖硬件预取机制来预取TLB条目。它必须使用预取指令明确的完成。就像数据和指令缓存,TLB可以表现为多个等级。正如数据缓存,TLB通常表现为两种形式:指令TLB(ITLB)和数据TLB(DTLB)。高级的TLB像L2TLB通常是统一的,就像其他的缓存情形一样。
使用TLB的注意事项
TLB是以处理器为核心的全局资源。所有运行于处理器的线程与进程使用同一个TLB。由于虚拟到物理地址的转换依赖于设置的是哪一种页表树,如果页表变化了,CPU不能盲目的重复使用缓存的条目。每个进程有一个不同的页表树(不算在同一个进程中的线程),内核与内存管理器VMM(管理程序)也一样,如果存在的话。也有可能一个进程的地址空间布局发生变化。有两种解决这个问题的办法:
- 当页表树变化时TLB刷新。
- 扩充 TLB 项目的标签,以额外且唯一地识别它们所指涉到的分页表树。
第一种情况,只要执行一个上下文切换TLB就被刷新。因为大多数OS中,从一个线程/进程到另一个的切换需要执行一些核心代码,TLB刷新被限制在进入或离开核心地址空间时。在虚拟化的系统上,当系统核心必须呼叫 VMM、并在返回的途中时,这也会发生。如果内核和/或内存管理器没有使用虚拟地址,或者当进程或内核调用系统/内存管理器时,能重复使用同一个虚拟地址(即,定址空间被重叠了),TLB必须被刷新。TLB 必须在离开系统核心或 VMM 后,处理器恢复一个不同的进程或系统核心的执行时被刷新。
刷新TLB高效但昂贵。例如,当执行一个系统调用,触及的内核代码可能仅限于几千条指令,或许少许新页面(或一个大的页面,像某些结构的Linux的就是这样)。这个工作将替换触及页面的所有TLB条目。对Intel带128ITLB和256DTLB条目的Core2架构,完全的刷新意味着多于100和200条目(分别的)将被不必要的刷新。当系统调用返回同一个进程,所有那些被刷新的TLB条目可能被再次用到,但它们没有了。内核或内存管理器常用的代码也一样。所有那些被刷新的 TLB 项目都能够被再次用到,但它们将会被丢掉。对于在系统核心或 VMM 中经常用到的程序码亦是如此。即使内核与内存管理器的页表通常不会改变。因此理论上说,TLB条目可以被保持一个很长时间。但在每次进入系统核心时,TLB 也必须从零开始填入。这也解释了为何现今处理器中的 TLB cache并没有更大的原因:程序的执行时间非常可能不会长到足以填入这所有的项目。
这个事实当然不会逃出 CPU 架构师的掌心。最佳化cache刷新的一个可能性是,单独令 TLB 项目失效。例如,如果内核代码与数据落于一个特定的地址范围,只有落入这个地址范围的页面必须被清除出TLB。这只需要比较标签,因此不是很昂贵。如果地址空间的一部分发生了变化,例如,通过调用munmap,这种方法也很有用。
更好的解决方法是为TLB访问扩展标签。如果除了虚拟地址的一部分之外,一个唯一的对应每个页表树的标识(如一个进程的地址空间)被添加,TLB将根本不需要完全刷新。内核,内存管理程序,和独立的进程都可以有唯一的标识。这种场景唯一的问题在于,TLB标签可以获得的位数异常有限,但是地址空间的位数却不是。这意味着一些标识的再利用是有必要的。这种情况发生时TLB必须部分刷新(如果可能的话)。所有带有再利用标识的条目必须被刷新,但是希望这是一个非常小的集合。
当多个进程运行在系统中时,这种扩展的TLB标签具有一般优势。如果每个可运行进程对内存的使用(因此TLB条目的使用)做限制,进程最近使用的TLB条目,当其再次列入计划时,有很大机会仍然在TLB。但还有两个额外的优势:
- 特殊的地址空间,像内核和内存管理器使用的那些,经常仅仅进入一小段时间;之后控制经常返回初始化此次调用的地址空间。没有标签,就有两次TLB刷新操作。有标签,调用地址空间缓存的转换地址将被保存,而且由于内核与内存管理器地址空间根本不会经常改变TLB条目,系统调用之前的地址转换等等可以仍然使用。
- 当同一个进程的两个线程之间切换时,TLB刷新根本就不需要。虽然没有扩展TLB标签时,进入内核的条目会破坏第一个线程的TLB的条目。
有些处理器在一些时候实现了这些扩展标签。AMD给帕西菲卡(Pacifica)虚拟化扩展引入了一个1位的扩展标签。在虚拟化的上下文中,这个1位的地址空间ID(ASID)被用来从客户域区别出内存管理程序的地址空间。这使得OS能够避免在每次进入内存管理程序的时候(例如为了处理一个页面错误)刷新客户的TLB条目,或者当控制回到客户时刷新内存管理程序的TLB条目。这个架构未来会允许使用更多的位。其它主流处理器很可能会随之适应并支持这个功能。
影响TLB性能
有一些因素会影响TLB性能。第一个是页面的大小。显然页面越大,装进去的指令或数据对象就越多。所以较大的页面大小减少了所需的地址转换总次数,即需要更少的TLB缓存条目。大多数架构允许使用多个不同的页面尺寸;一些尺寸可以并存使用。例如,x86/x86-64处理器有一个普通的4kB的页面尺寸,但它们也可以分别用4MB和2MB页面。IA-64 和 PowerPC允许如64kB的尺寸作为基本的页面尺寸。
然而,大页面尺寸的使用也随之带来了一些问题。用作大页面的内存范围必须是在物理内存中连续的。如果物理内存管理的单元大小升至虚拟内存页面的大小,浪费的内存数量将会增长。各种内存操作(如加载可执行文件)需要页面边界对齐。这意味着平均每次映射浪费了物理内存中页面大小的一半。这种浪费很容易累加;因此它给物理内存分配的合理单元大小划定了一个上限。
在x86-64结构中增加单元大小到2MB来适应大页面当然是不实际的。这是一个太大的尺寸。但这转而意味着每个大页面必须由许多小一些的页面组成。这些小页面必须在物理内存中连续。以4kB单元页面大小分配2MB连续的物理内存具有挑战性。它需要找到有512个连续页面的空闲区域。在系统运行一段时间并且物理内存开始碎片化以后,这可能极为困难(或者不可能)
因此在 Linux 上,有必要在系统启动的时候使用特殊的 hugetlbfs 档案系统来分配这些大分页。一个固定数量的实体分页会被保留来专门作为大虚拟分页来使用。这绑住了可能不会一直用到的资源。这也是个有限的池(pool);增加它通常代表著重新启动系统。尽管如此,在效能贵重、资源充足、且麻烦的设置不是个大阻碍的情况下,庞大的分页便为大势所趋。数据库服务器就是个例子。
1 | $ eu-readelf -l /bin/ls |
提高最小的虚拟分页大小(对比于可选的大分页)也有它的问题。memory映射操作(例如,载入应用程序)必须遵循这些分页大小。不可能有更小的映射。一个可执行程序不同部分的位置 –– 对大多架构而言 –– 有个固定的关系。若是分页大小增加到超过在可执行程序或者 DSO 创建时所考虑的大小时,就无法执行载入操作。将这个限制记在心上是很重要的。图 4.3 显示了能够如何决定一个 ELF 二进位资料(binary)的对齐需求的。它被编码在 ELF 的程序标头(header)。在这个例子中,一个 x86-64 的二进位资料,值为 ,与处理器所支援的最大分页大小相符。
使用较大的分页大小有个次要的影响:分页表树的层级数量会被减低。由于对应到分页偏移量的虚拟地址部分增加了,就没有剩下那么多需要透过分页目录处理的bit了。这表示,在一次 TLB 错失的情况下,必须完成的工作总量减少了。
除了使用大分页尺寸外,也可能借由将同时用到的资料搬移到较少的分页上,以减少所需的 TLB 项目数量。这类似于我们先前讨论的针对cache使用的一些最佳化。 只有现在对齐需求是巨大的。 考虑到 TLB 项目的数量非常少,这会是个重要的最佳化。
虚拟化的影响
操作系统映像的虚拟化将变得越来越普遍;这意味着在图片中添加了另一层内存处理。进程(基本监狱)或操作系统容器的虚拟化不属于这一类,因为只涉及一个操作系统。Xen或KVM等技术——无论有没有处理器的帮助——都可以执行独立的操作系统映像。在这种情况下,只有一个软件可以直接控制对物理内存的访问。
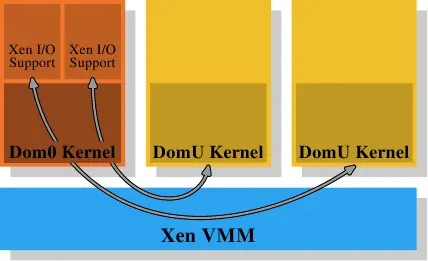
在Xen的例子中(参见图4.4),Xen VMM就是那个软件。不过,VMM本身并没有实现许多其他硬件控制。与其他早期系统(以及Xen VMM的第一次重新租用)上的VM不同,内存和处理器之外的硬件由享有特权的Dom0域控制。现在,这基本上与没有特权的DomU内核一样,就内存处理方面而言,它们没有什么不同。这里重要的是,VMM将物理内存分配给Dom0和DomU内核,然后它们自己实现通常的内存处理,就好像它们在处理器上直接运行一样。
为了实现完成虚拟化所需的各个域之间的分隔,Dom0和DomU内核中的内存处理不具有无限制的物理内存访问权限。VMM不是通过分发独立的物理页并让客户OS处理地址的方式来分发内存;这不能提供对错误或欺诈客户域的防范。替代的,VMM为每一个客户域创建它自己的页表树,并且用这些数据结构分发内存。好处是对页表树管理信息的访问能得到控制。如果代码没有合适的特权,它不能做任何事。 在虚拟化的Xen支持中,这种访问控制已被开发,不管使用的是参数的或硬件的(又名全)虚拟化。客户域以意图上与参数的和硬件的虚拟化极为相似的方法,给每个进程创建它们的页表树。每当客户OS修改了VMM调用的页表,VMM就会用客户域中更新的信息去更新自己的影子页表。这些是实际由硬件使用的页表。显然这个过程非常昂贵:每次对页表树的修改都需要VMM的一次调用。而没有虚拟化时内存映射的改变也不便宜,它们现在变得甚至更昂贵。 考虑到从客户OS的变化到VMM以及返回,其本身已经相当昂贵,额外的代价可能真的很大。这就是为什么处理器开始具有避免创建影子页表的额外功能。这样很好不仅是因为速度的问题,而且它减少了VMM消耗的内存。Intel有扩展页表(EPTs),AMD称之为嵌套页表(NPTs)。基本上两种技术都具有客户OS的页表,来产生虚拟的物理地址。然后通过每个域一个EPT/NPT树的方式,这些地址会被进一步转换为真实的物理地址。这使得可以用几乎非虚拟化情境的速度进行内存处理,因为大多数用来内存处理的VMM条目被移走了。它也减少了VMM使用的内存,因为现在一个域(相对于进程)只有一个页表树需要维护。 额外的地址转换步骤的结果也存储于TLB。那意味着TLB不存储虚拟物理地址,而替代以完整的查询结果。已经解释过AMD的帕西菲卡扩展为了避免TLB刷新而给每个条目引入ASID。ASID的位数在最初版本的处理器扩展中是一位;这正好足够区分VMM和客户OS。Intel有服务同一个目的的虚拟处理器ID(VPIDs),它们只有更多位。但对每个客户域VPID是固定的,因此它不能标记单独的进程,也不能避免TLB在那个级别刷新。
对虚拟OS,每个地址空间的修改需要的工作量是一个问题。但是还有另一个内在的基于VMM虚拟化的问题:没有什么办法处理两层的内存。但内存处理很难(特别是考虑到像NUMA一样的复杂性,见第5部分)。Xen方法使用一个单独的VMM,这使最佳的(或最好的)处理变得困难,因为所有内存管理实现的复杂性,包括像发现内存范围之类“琐碎的”事情,必须被复制于VMM。OS有完全成熟的与最佳的实现;人们确实想避免复制它们。
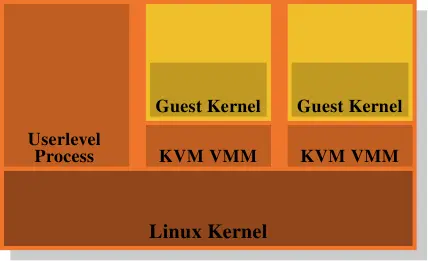
这就是为什么对VMM/Dom0模型的分析是这么有吸引力的一个选择。图4.5显示了KVM的Linux内核扩展如何尝试解决这个问题的。并没有直接运行在硬件之上且管理所有客户的单独的VMM,替代的,一个普通的Linux内核接管了这个功能。这意味着Linux内核中完整且复杂的内存管理功能,被用来管理系统的内存。客户域运行于普通的用户级进程,创建者称其为“客户模式”。虚拟化的功能,参数的或全虚拟化的,被另一个用户级进程KVM VMM控制。这也就是另一个进程用特别的内核实现的KVM设备,去恰巧控制一个客户域。
这个模型相较Xen独立的VMM模型好处在于,即使客户OS使用时,仍然有两个内存处理程序在工作,只需要在Linux内核里有一个实现。不需要像Xen VMM那样从另一段代码复制同样的功能。这带来更少的工作,更少的bug,或许还有更少的两个内存处理程序接触产生的摩擦,因为一个Linux客户的内存处理程序与运行于裸硬件之上的Linux内核的外部内存处理程序,做出了相同的假设。
总的来说,程序员必须清醒认识到,采用虚拟化时,内存操作的代价比没有虚拟化要高很多。任何减少这个工作的优化,将在虚拟化环境付出更多。随着时间的过去,处理器的设计者将通过像EPT和NPT技术越来越减少这个差距,但它永远都不会完全消失。
NUMA 支持
在第二部分中,我们看到在某些机器上,访问物理内存特定区域的成本取决于访问的来源。这种类型的硬件需要操作系统和应用程序特别注意。我们将从 NUMA 硬件的一些细节开始,然后再介绍 Linux 内核为 NUMA 提供的一些支持。
NUMA 硬件
非均匀内存体系结构越来越普遍。在最简单的 NUMA 形式中,处理器可以具有本地内存(参见图2.3),其访问成本比其他处理器本地内存要便宜。这种类型的 NUMA 系统的成本差异并不高,即 NUMA 因子很低。
NUMA 还特别用于大型机器。我们已经描述了许多处理器访问同一内存所带来的问题。对于商用硬件,所有处理器都将共享同一个北桥(暂不考虑 AMD Opteron NUMA 节点,它们有自己的问题)。这使得北桥成为一个严重的瓶颈,因为所有内存流量都通过它进行路由。当然,大型机器可以使用自定义硬件代替北桥,但是,除非使用的内存芯片具有多个端口,即它们可以从多个总线中使用,否则仍然存在瓶颈。多端口 RAM 很复杂,成本很高,因此几乎不会使用。
复杂度的下一个增加是 AMD 使用的模型,其中一种互连机制(在 AMD 的情况下是 Hypertransport,这是他们从 Digital 获得许可的技术)为未直接连接到 RAM 的处理器提供访问。这种方式可以形成的结构的大小受到限制,除非想任意增加直径(即任意两个节点之间的最大距离)。
一种连接节点的高效拓扑(topology)为超立方体(hypercube),其将节点的数量限制在 ,其中 为每个节点拥有的交互连接介面的数量。以所有有著 个 CPU 与 条交互连接的系统而言,超立方体拥有最小的直径。图 5.1 显示了前三种超立方体。每个超立方体拥有绝对最小(the absolute minimum)的直径 。AMD 第一世代的 Opteron 处理器,每个处理器拥有三条超传输连结。至少有一个处理器必须有个附属在一条连结上的南桥,代表 –– 目前而言 –– 一个 的超立方体能够直接且有效率地实作。下个世代将在某个时间点拥有四条连结,届时将可能有 的超立方体。
但这并不意味着不支持更大的处理器积累。一些公司已经开发了交叉开关,允许使用更大的处理器集合(例如Newisys的Horus)。但是这些交叉开关会增加NUMA因素,并且在一定数量的处理器上不再有效。
下一步是连接CPU组并为它们实现共享内存。所有这样的系统都需要专用硬件,绝不是商品系统。这样的设计存在多个复杂度级别。一个仍然非常接近商品机的系统是IBM x445和类似的机器。它们可以作为普通的4U,8路机器购买,带有x86和x86-64处理器。然后可以将两个(在某些时候最多四个)这样的机器连接起来,以共享内存的方式作为一个单一的机器。所使用的互连引入了一个显著的NUMA因素,这是操作系统以及应用程序必须考虑的。
在另一端的系统中,像SGI的Altix就是专门设计用于互连。SGI的NUMAlink互连结构非常快且延迟低,这些都是高性能计算(HPC)的要求,特别是当使用消息传递接口(MPI)时。缺点当然是这种复杂性和专业化非常昂贵。它们可以实现相对较低的NUMA因素,但由于这些机器可以拥有数千个CPU并且互连的容量有限,NUMA因素实际上是动态的,取决于工作负载而可能达到不可接受的水平。
更常见的解决方案是使用高速网络连接商品机集群。但这些不是NUMA机器;它们不实现共享地址空间,因此不属于本文讨论的任何类别。
操作系统对 NUMA 的支援
为了支持NUMA机器,操作系统必须考虑内存的分布性质。例如,如果在给定的处理器上运行一个进程,则分配给该进程地址空间的物理RAM应来自本地内存。否则,每个指令都必须访问远程内存以获取代码和数据。在NUMA机器中存在需要考虑的特殊情况。DSO的文本段(text segment)在一台机器的实体 RAM 中通常正好出现一次。但是,如果DSO由所有CPU上的进程和线程使用(例如基本运行库如libc),这意味着除了少数处理器外,其他处理器都必须具有远程访问。理想情况下,操作系统应该将这些DSO“镜像”到每个处理器的物理RAM中,并使用本地副本。这是一种优化而不是要求,并且通常难以实现。它可能不被支持或仅以有限的方式支持。
为避免情况恶化,操作系统不应将进程或线程从一个节点迁移至另一个节点。在普通的多处理器机器上,操作系统已经尝试避免迁移进程,因为从一个处理器迁移到另一个处理器意味着缓存内容会丢失。如果负载分配需要将进程或线程从处理器迁移,操作系统通常可以选择具有足够剩余容量的任意新处理器。在NUMA环境中,选择新处理器的范围略有限制。新选择的处理器不应该比旧处理器更高地访问进程正在使用的内存,这限制了可选目标列表。如果没有可用满足该标准的空闲处理器,则操作系统别无选择,只能迁移到访问内存更昂贵的处理器。
在这种情况下,有两种可能的方法。首先,可以希望情况是暂时的,并且进程可以迁回到更合适的处理器。或者,操作系统也可以将进程的内存迁移到更靠近新使用的处理器的物理页面。这是一项非常昂贵的操作。可能需要复制大量的内存,尽管不一定在一步完成。在此过程中,进程至少要被暂停,以便正确迁移旧页面的修改。还有一系列其他要求,以使页面迁移高效快速。简而言之,除非确实需要,否则操作系统应该避免进行此操作。
通常情况下,Linux内核不会假设所有在NUMA机器上运行的进程都使用相同数量的内存,因此在进程分布在不同处理器上的情况下,内存使用情况也是不平衡的。实际上,除非在HPC领域等特定应用中,运行在机器上的应用程序所使用的内存将会非常不平衡。一些应用程序会使用大量的内存,而其他应用程序则几乎不使用内存。如果总是将内存分配到发出请求的处理器上,这将最终导致问题。当运行大型进程的节点内存不足时,系统将出现问题。
为了应对这些严重的问题,默认情况下不会仅在本地节点上分配内存。为了利用系统的所有内存, 默认策略是将内存分割成多个条带。这可以保证所有系统内存的使用是均衡的。副作用是可以在处理器之间自由迁移进程,因为平均而言,所有使用的内存的访问成本都不会改变。对于小的NUMA因子,分条是可以接受但仍不是最优的(请参见第5.4节中的数据)。
这是一种负优化,有助于系统避免严重问题并使其在正常操作下更可预测。但是,它确实降低了整个系统的性能,在某些情况下甚至会显著降低。这就是为什么Linux允许每个进程选择内存分配规则。进程可以为自身及其子进程选择不同的策略。我们将在第6节中介绍可以用于此的接口。
消息发布
内核通过 sys 伪文件系统(sysfs)发布有关处理器缓存的信息,其路径如下:
1 | /sys/devices/system/cpu/cpu*/cache |
在 6.2.1 节,我们会看到能用来查询不同cache大小的介面。这里重要的是cache的拓朴。上面的目录包含了列出 CPU 拥有的不同cache资讯的子目录(叫做 index*)。档案 type、level、与 shared_cpu_map 是在这些目录中与拓朴有关的重要档案。一个 Intel Core 2 QX6700 的资讯看起来就如表 5.1。
type | level | shared_cpu_map | ||
|---|---|---|---|---|
cpu0 | index0 | Data | 1 | 00000001 |
index1 | Instruction | 1 | 00000001 | |
index2 | Unified | 2 | 00000003 | |
cpu1 | index0 | Data | 1 | 00000002 |
index1 | Instruction | 1 | 00000002 | |
index2 | Unified | 2 | 00000003 | |
cpu2 | index0 | Data | 1 | 00000004 |
index1 | Instruction | 1 | 00000004 | |
index2 | Unified | 2 | 0000000c | |
cpu3 | index0 | Data | 1 | 00000008 |
index1 | Instruction | 1 | 00000008 | |
index2 | Unified | 2 | 0000000c | |
sysfs 资讯这份资料的意义如下:
- 每颗处理器核[2]拥有三个cache:L1i、L1d、L2。
- L1d 与 L1i cache没有被任何其它的处理器核所共享 –– 每颗处理器核有它自己的一组cache。这是由
shared_cpu_map中的bit图(bitmap)只有一个被设置的bit所暗示的。 cpu0与cpu1的 L2 cache是共享的,正如cpu2与cpu3上的 L2 一样。
若是 CPU 有更多cache阶层,也会有更多的 index* 目录。
type | level | shared_cpu_map | ||
|---|---|---|---|---|
cpu0 | index0 | Data | 1 | 00000001 |
index1 | Instruction | 1 | 00000001 | |
index2 | Unified | 2 | 00000001 | |
cpu1 | index0 | Data | 1 | 00000002 |
index1 | Instruction | 1 | 00000002 | |
index2 | Unified | 2 | 00000002 | |
cpu2 | index0 | Data | 1 | 00000004 |
index1 | Instruction | 1 | 00000004 | |
index2 | Unified | 2 | 00000004 | |
cpu3 | index0 | Data | 1 | 00000008 |
index1 | Instruction | 1 | 00000008 | |
index2 | Unified | 2 | 00000008 | |
cpu4 | index0 | Data | 1 | 00000010 |
index1 | Instruction | 1 | 00000010 | |
index2 | Unified | 2 | 00000010 | |
cpu5 | index0 | Data | 1 | 00000020 |
index1 | Instruction | 1 | 00000020 | |
index2 | Unified | 2 | 00000020 | |
cpu6 | index0 | Data | 1 | 00000040 |
index1 | Instruction | 1 | 00000040 | |
index2 | Unified | 2 | 00000040 | |
cpu7 | index0 | Data | 1 | 00000080 |
index1 | Instruction | 1 | 00000080 | |
index2 | Unified | 2 | 00000080 | |
sysfs 资讯对于一个四槽、双核的 Opteron 机器,cache资讯看起来如表 5.2。可以看出这些处理器也有三种cache:L1i、L1d、L2。没有处理器核共享任何阶层的cache。这个系统有趣的部分在于处理器拓朴。少了这个额外信息,就无法理解cache资料。sys 档案系统将这个信息放在下面这个文件中。
1 | /sys/devices/system/cpu/cpu*/topology |
表格5.3展示了SMP Opteron机器在这个层次结构中的有趣文件。
physical_ | core_id | core_ | thread_ | |
|---|---|---|---|---|
cpu0 | 0 | 0 | 00000003 | 00000001 |
cpu1 | 1 | 00000003 | 00000002 | |
cpu2 | 1 | 0 | 0000000c | 00000004 |
cpu3 | 1 | 0000000c | 00000008 | |
cpu4 | 2 | 0 | 00000030 | 00000010 |
cpu5 | 1 | 00000030 | 00000020 | |
cpu6 | 3 | 0 | 000000c0 | 00000040 |
cpu7 | 1 | 000000c0 | 00000080 |
sysfs 资讯将表 5.2 与 5.3 摆在一起,我们能够发现
- 没有 CPU 拥有 HT (
thethread_siblingsbit图有一个bit被设置)、 - 这个系统实际上共有四个处理器(
physical_package_id0 到 3)、 - 每个处理器有两颗核、以及没有处理器核共享任何cache。
这正好与较早期的 Opteron 一致。
迄今为止提供的数据完全缺乏有关此机器NUMA性质的信息。任何SMP Opteron机器都是NUMA机器。对于这些数据,我们必须查看“sys”文件系统的另一部分,该部分存在于NUMA机器下面的层次结构中。
1 | /sys/devices/system/node |
该目录包含系统上每个NUMA节点的子目录。在节点特定的目录中,有许多文件。对于前两个表中描述的Opteron机器,其重要文件及其内容如表5.4所示。
cpumap | distance | |
|---|---|---|
node0 | 00000003 | 10 20 20 20 |
node0 | 0000000c | 20 10 20 20 |
node2 | 00000030 | 20 20 10 20 |
node3 | 000000c0 | 20 20 20 10 |
sysfs 资讯这些信息将所有其他信息联系在一起;现在我们已经有了机器架构的完整图像。我们已经知道机器有四个处理器。每个处理器构成自己的节点,如在node*目录中的cpumap文件中的值所示。这些目录中的distance文件包含一组值,每个节点一个,表示在各个节点上的内存访问成本。在这个例子中,所有本地内存访问的成本都是10,所有对任何其他节点的远程访问的成本都是20。[3] 这意味着,即使处理器被组织成二维超立方体(见图5.1),不直接连接的处理器之间的访问也不会更加昂贵。这些成本的相对值可用作访问时间实际差异的估计。所有这些信息的准确性是另一个问题。
远端存取成本
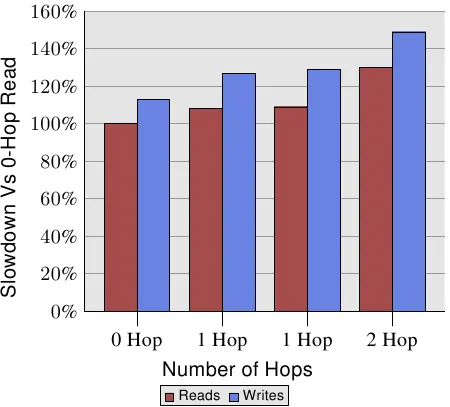
不过,距离是有关系的。AMD 在1中提供了一台四槽机器的NUMA成本。写入操作的数据显示在图 5.2。写入比读取还慢,这并不让人意外。有趣的部分在于 1 与 2 跳(1- and 2-hop)情况下的成本。两个 1 跳的成本实际上有略微不同。细节见 1。2 跳读取与写入(分别)比 0 跳读取慢了 30% 与 49%。2 跳写入比 0 跳写入慢了 32%、比 1 跳写入慢了 17%。处理器和内存节点的相对位置可能会产生很大的差异。来自AMD的下一代处理器将每个处理器配备四个一致的HyperTransport链接。在这种情况下,四个插槽机器的直径为1。但有八个插槽的话,同样的问题又再次出现,因为具有八个节点的超立方体的直径为三。
所有这些信息都能够取得,但用起来很麻烦。在 6.5 节,我们会看到较容易存取与使用这个信息的界面。
1 | 00400000 default file=/bin/cat mapped=3 N3=3 |
系统提供的最后一条信息是进程本身的状态。可以确定内存映射文件、写时复制(COW)[4]页面和匿名内存在系统中的节点上如何分布。每个进程都有一个文件 /proc/PID/numa_maps,其中PID是进程的ID,如图5.2所示。
文件中重要的信息是N0到N3的值,它们表示在节点0到3上分配的内存区域的页面数量。很有可能该程序在节点3上的核心上执行,程序本身和脏页面都分配在该节点上。只读映射,如ld-2.4.so和libc-2.4.so的第一个映射以及共享文件locale-archive,则分配在其他节点上。
如我们在图5.3中所见,对于1和2跳读取,跨节点的读取性能分别下降了9%和30%。对于执行,这些读取是必需的,如果L2缓存未命中,则每个缓存行会产生这些额外的成本。如果内存远离处理器,则所有大型工作负载的成本都将增加9%/30%。
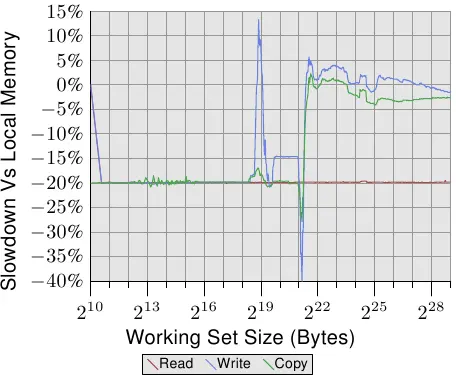
为了看到现实世界中的影响,我们可以像3.5.1节那样测量带宽,但这次是在内存位于远程节点,距离一个跳跃的情况下进行的。将此测试的结果与使用本地内存的数据进行比较,可以在图5.4中看到。这些数字在两个方向上都有一些很大的峰值,这是测量多线程代码的问题,可以忽略不计。这个图表中的重要信息是读操作总是比本地内存慢20%。这比图5.3中的9%要慢得多,这很可能不是连续读写操作的数字,可能指的是旧的处理器版本。只有AMD知道。
以塞得进cache的工作集大小而言,写入与复制操作的效能也慢了 20%。当工作集大小超过cache大小时,写入效能不再显著地慢于本地节点上的操作。互连的速度足以跟上memory的速度。主要因素是花费在等待主memory的时间。
参考
- [1] Performance Guidelines for AMD Athlon™ 64 and AMD Opteron™ ccNUMA Multiprocessor Systems. Advanced Micro Devices, June 2006.
- [3] Vinodh Cuppu, Bruce Jacob, Brian Davis, and Trevor Mudge. High-Performance DRAMs in Workstation Environments. IEEE Transactions on Computers, 50(11):1133–1153, November 2001.
- [6] M. Dowler. Introduction to DDR-2: The DDR Memory Replacement, May 2004.
- [7] Ulrich Drepper. Futexes Are Tricky, December 2005
- [11] Joe Gebis and David Patterson. Embracing and Extending 20th-Century Instruction Set Architectures. Computer, 40(4):68–75, April 2007. 8.4
- [12] David Goldberg. What Every Computer Scientist Should Know About Floating-Point Arithmetic. ACM Computing Surveys, 23(1):5–48, March 1991.
- [14] Ram Huggahalli, Ravi Iyer, and Scott Tetrick. Direct Cache Access for High Bandwidth Network I/O, 2005.
- [15] Intel R© 64 and IA-32 Architectures Optimization Reference Manual. Intel Corporation, May 2007.
- [17] Caol ́an McNamara. Controlling symbol ordering, April 2007.
- [18] Double Data Rate (DDR) SDRAM MT46V. Micron Technology, 2003. Rev. L 6/06 EN.
- [19] Jon “Hannibal” Stokes. Ars Technica RAM Guide, Part II: Asynchronous and Synchronous DRAM, 2004.
- [20] Static random access memory - Wikipedia, 2006.