What Every Programmer Should Know About Memory (3)
程序开发者能做些什么?
在前面几节的描述之后,无疑地,程序开发者有非常非常多 – 正向或者负向地 –– 影响程序效能的机会。而这里仅讨论与memory有关的操作。我们将会全面地解释这些部分,由最底层的物理 RAM 存取以及 L1 cache开始,一路涵盖到影响memory管理的操作系统功能。
绕过cache
当数据被产生并且没有(立即)再次使用时,内存存储操作首先读取完整的缓存行,然后修改缓存的数据,这点对性能不利。此操作将可能会再次需要的数据从缓存中淘汰,将缓存让给那些短期内不会再次被用到的数据。对于大型数据结构尤其如此,如矩阵,它们被填充,然后再使用。在矩阵的最后一个元素被填充之前,第一个元素就会因为矩阵太大被踢出cache,导致写入cache无效。
对于这类情况,处理器提供对**非暂存(non-temporal)**写入操作的支援。在这种情况下,非暂存指的是数据不会很快被重用,所以没有任何缓存它的理由。这些非暂存的写入操作不会先读取cache行然后才修改它;相反,新内容直接写入内存。
这听起来可能很昂贵,但并不一定如此。处理器会试著使用写合并(见 3.3.3 节)来填入整个cache行。若是成功,那么memory读取操作是完全不必要的。如 x86 以及 x86-64 架构,gcc 提供若干intrinsic(编译器内部函数):
1 |
|
最有效率地使用这些指令的情况是一次处理大量数据。数据从内存加载,在一个或多个步骤中处理,然后写回内存。数据“流”过处理器,因此有内在函数的名称。
内存地址必须各自对齐至 8 或 16 byte。在使用多媒体扩充(multimedia extension)的程序码中,也可以用这些非暂存的版本替换通常的 _mm_store_* 指令。我们并没有在 A.1 节的矩阵相乘程序中这么做,因为写入的值会在短时间内被再次使用。这是一个使用流指令没有用的例子。6.2.1 节会更加深入这段程序码。
处理器的写合并缓冲区可以将部分写入cache行的请求延迟一小段时间。一个接着一个执行所有修改单一cache行的指令,以令合并写入能真的发挥功用通常是必要的。以下是一个如何实践的例子:
1 |
|
假设指针 p 被适当地对齐,调用这个函数会将指向的cache行中的所有byte设为 c。合并写入逻辑会看到四个生成的 movntdq 指令,并仅在最后一个指令被执行之后,才对memory发出写入命令。总而言之,这段程序不仅避免在写入前读取cache行,也避免cache被并非立即需要的数据污染。这在某些情况下会有巨大的好处。一个经常使用这项技术的例子是C函数库中的memset函数,它在处理大块memory时使用如上所述的代码。
一些架构提供了专门的解决方案。PowerPC架构定义了可用于清除整个缓存行的dcbz指令。这个指令不会真的绕过cache,因为cache行仍会被分配来存放结果,但没有任何数据会从memory被读出来。它比非暂存存储指令更受限制,因为缓存行只能设置为全零,并且它会调整缓存(如果数据是非时态的),但不需要写合并来实现。
为了查看非暂存指令的运行情况,我们将查看一个新的测试,该测试用于测量对矩阵的写入性能(矩阵被组织为一个二维数组)。编译器在内存中布置矩阵,以便最左边(第一个)索引寻址内存中元素按顺序排列的行。右边(第二个)索引行中的元素。测试程序以两种方式迭代矩阵:
- 增加内部循环中的列索引
- 增加内部循环中的行索引。
其行为如图 6.1 所示。
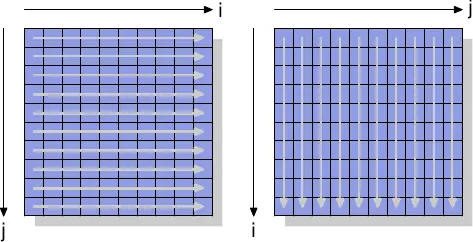
我们测量初始化3000×3000 矩阵所需的时间。为了了解内存的行为,我们使用不使用缓存的存储指令。在IA-32处理器上,“non-temporal hint”用于此目的。为了进行对比,我们还测量普通的存储操作。结果见表6.1。
| 内部顺序循环 | ||
|---|---|---|
| 行 | 列 | |
| 一般 | 0.048s | 0.127s |
| 非暂存 | 0.048s | 0.160s |
对于使用缓存的正常写入,我们看到了预期的结果:如果顺序使用内存,我们会得到更好的结果,整个操作耗时0.048秒转换下大约750MB/s,相比之下,或多或少的随机访问需要0.127秒(大约280MB/s)。矩阵已经大到缓存基本上失效。
这里我们主要感兴趣的部分是绕过缓存的写入。令人惊讶的是,这里的顺序访问和使用缓存的情况下一样快。造成这种结果的原因是进程或正在执行写合并,如上所述。此外,非暂存写入的内存排序规则被放宽了: 程序需要显式插入内存屏障(x86和x86-64处理器的sfence指令)。这意味着处理器在写回数据时有更多的自由,从而尽可能地使用可用带宽。
在内部循环中按列访问的情况下,情况就不同了。未缓存访问的结果比缓存访问的结果慢得多(0.16秒,约225MB/s)。在这里,我们可以看到不可能进行写合并,每个存储单元必须单独寻址。这需要不断地在RAM芯片中在所有相关延迟下选择新行。结果比缓存运行的结果差25%。
在读取方面,直到最近,处理器除了使用非暂存访问(NTA)预取指令的弱提示之外,还缺乏相应的支持。没有与写入合并对等的读取操作,这对于不可被缓存的内存,如内存映射(memory-mapped)I/O,来说尤其糟糕。Intel 附带 SSE4.1 扩充引入 NTA 载入。它们以一些流载入缓冲区(streaming load buffer)实现;每个缓冲区都包含一条cache line。给定cache line的第一个 movntdqa 指令会将cache line载入一个缓冲区,可能会替换另一条cache line。随后,对同一个cache line、以 16 byte对齐的存取操作将会由载入缓冲区以少量的成本来提供服务。除非有其他原因,否则cache line不会被加载到缓存中,从而可以在不污染缓存的情况下加载大量内存。编译器为此指令提供了一个intrinsic函数:
1 |
|
这个intrinsic函数应该要以16字节块的地址作为参数多次执行,直到每个缓存行都被读取。在这时才应该开始处理下一个缓存行。由于有几个流读缓冲区,因此可以同时从两个内存位置读取。
我们应该从这个实验中得到的是,现代CPU非常好地优化了非缓存写入,最近甚至可以优化读取访问,只要它们是顺序操作。当处理只使用一次的大型数据结构时,这些知识会非常有用。其次,缓存可以帮助降低随机内存访问的部分(但不是全部)成本。由于RAM访问的实现,本例中的随机访问速度降低了70%。在实现改变之前,应该尽可能避免随机访问。
在关于预取的章节中,我们将再次查看非暂存标志。
cache 访问
希望提高程序性能的程序员会发现最好关注影响一级缓存的变化,因为这些变化可能会产生最好的结果。在将讨论扩展到其他级别之前,我们将首先讨论它。显然,一级缓存的所有优化也会影响其他缓存。所有内存访问的主题都是一样的:提高局部性(空间和时间),对齐代码和数据。
优化一级数据缓存访问
在 3.3 节,我们已经看过 L1d cache的有效使用能够提升效能。在本节中,我们将展示什么样的代码更改有助于提高性能。延续上一节,我们首先聚焦在顺序访问内存的优化。如第3.3节的数字所示,当顺序访问内存时,处理器会自动预取数据。
使用的示例代码是矩阵相乘。我们使用两个 双元素的平方矩阵。对于那些忘记数学的人,给定元素为 与 的矩阵 与 ,,乘积为:
一个直观的 C 实现看起来可能像这样:
1 | for (i = 0; i < N; ++i) |
两个输入矩阵为 mul1 与 mul2。假定结果矩阵 res 全被初始化为零。这是一个很好的简单实现。但是很明显,我们会遇到图6.1中解释的问题。当mul1被顺序访问时,inner循环将增加mul2的行数。这意味着mul1像图6.1中的左矩阵一样处理,而mul2像右矩阵一样处理。这可能不太好。
有一种可能的补救方法可以很容易地尝试。由于矩阵中的每个元素都被多次访问,在使用第二个矩阵mul2之前,重新排列(“转置”,用数学术语来说)可能是值得的。
在转置之后(通常以上标「T」表示),我们现在顺序地迭代两个矩阵。就 C 程序而言,现在看起来像这样:
1 | double tmp[N][N]; |
我们创建一个临时变量来存储转置矩阵。这需要使用额外的内存,但这一成本有望收回,因为每列1000次非顺序访问更昂贵(至少在现代硬件上)。一些性能测试的时间。在主频为2666MHz的英特尔酷睿2上的结果是(以时钟周期为单位)
| 原始 | 转置 | |
|---|---|---|
| 周期数 | 16,765,297,870 | 3,922,373,010 |
| 相对值 | 100% | 23.4% |
虽然只是个简单的矩阵转置,但我们能达到 76.6% 的加速!复制操作的损失完全被弥补。1000 次非循序存取真的很伤。
下个问题是,我们是否能做得更好。无论如何,我们确实需要一个不需额外复制的替代方法。我们并不是总有资源能进行复制:矩阵可能太大、或者可用的memory太小。
寻找替代实现应该从仔细检查所涉及的数学和原始实现执行的操作开始。三角数学知识使我们能够看到,只要每个加数(addend)恰好出现一次,结果矩阵的每个元素的加法执行顺序就无关紧要[1]。这个理解让我们能够寻找将执行在原始程序码内部循环的加法重新排列的解法。
现在,让我们来检验在原始程序码执行中的实际问题。被存取的 mul2 元素的顺序为:、、 … 、、、…。元素 与 $ (0, 1)$ 位于同一个cache行中,但在内部循环完成一轮的时候,这个cache行早已被逐出。以这个例子而言,每一轮内部循环都需要 –– 对三个矩阵的每一个而言 –– 1000 个cache行(Core 2 处理器为 64 byte)。这加起来远比 L1d 可用的 32k 还多。
但若是我们在执行内部循环的期间,一起处理中间循环的两次迭代呢?在这个情况下,我们使用两个来自必定在 L1d 中的cache行的 double 值。我们将 L1d 错失率减半。这当然是个改进,但视cache行的大小而定,也许仍不是我们能够得到的最好结果。Core 2 处理器有个cache行大小为 64 byte的 L1d。实际的大小能够使用sysconf (_SC_LEVEL1_DCACHE_LINESIZE)在执行期查询、或是使用命令行的 getconf 工具程序(utility),以让程序能够针对特定的cache行大小编译。
以 sizeof(double) 为 8 来说,为了完全利用cache行,我们应该展开内部循环 8 次。继续这个想法,为了有效地使用 res 矩阵。即,为了同时写入 8 个结果,我们也该展开外部循环 8 次。我们假设这里的cache行大小为 64,但这个程序码也能在 32 bytecache行的系统上运作,因为cache行也会被 100% 利用。一般来说,最好在编译期像这样使用 getconf 工具程序来写死(hardcode)cache行大小:
1 | gcc -DCLS=$(getconf LEVEL1_DCACHE_LINESIZE) ... |
如果二进制文件应该是通用的,应该使用最大的cache行大小。使用非常小的 L1d 表示并非所有数据都能塞进cache,但这种处理器无论如何都不适合高效能程序。我们写出的程序码看起来像这样:
1 |
|
这看起来很可怕。在某种程度上是的,仅仅是因为它包含了一些技巧。最明显的变化是我们现在有六个嵌套循环。外部循环以SM的间隔迭代(缓存行大小由sizeof(double)分割)。这将乘法分解成几个较小的问题,这些问题可以用更多的缓存局部性来处理。内部循环迭代外部循环的缺失索引。再次,有三个循环。这里唯一棘手的部分是k2和j2循环的顺序不同。这样做是因为在实际计算中,只有一个表达式依赖于k2,而两个依赖于j2。
这里其余的复杂性来自这样一个事实,即gcc在优化数组索引时并不十分聪明。通过引入额外变量rres、rmul1和rmul2,可能从内部循环中提取公共表达式来优化代码。C和C++语言的默认混淆现象规则无助于编译器做出这些决定(除非使用限制,否则所有指针访问都是混淆现象的潜在来源)。这就是为什么Fortran仍然是数值编程的首选语言:它使编写快速代码变得更容易[2]。
| 原始 | 转置 | 子矩阵 | 向量化 | |
|---|---|---|---|---|
| 周期数 | 16,765,297,870 | 3,922,373,010 | 2,895,041,480 | 1,588,711,750 |
| 相对值 | 100% | 23.4% | 17.3% | 9.47% |
所有努力所带来的成果能够在表 6.2 看到。借由避免复制,我们增加额外的 6.1% 效能。此外,我们不需要任何额外的memory。只要结果矩阵也能塞进memory,输入矩阵可以是任意大小的。这是我们现在已经达成的一个通用解法的一个必要条件。
在表 6.2 中还有一栏没有被解释过。大多现代处理器现今包含针对向量化(vectorization)的特殊支援。经常被标为多媒体扩充,这些特殊指令能够同时处理 2、4、8、或者更多值。这些经常是 SIMD(单指令多数据,Single Instruction, Multiple Data)操作。通过其他操作以正确的形式获得数据。英特尔处理器提供的SSE2指令可以在一次操作中处理两个double值。指令参考手册列出提供对这些 SSE2 指令存取的 intrinsic 函数。若是使用这些 intrinsic 函数,程序执行会变快 7.3%(相对于原始代码)。结果是程序运行时间为原始代码的10%。翻译成人们认识的数字,我们从 318 MFLOPS 提升到 3.35 GFLOPS。由于我们在这里仅对memory的影响有兴趣,程序的原始代码被放到 A.1 节。
应该注意的是,在最后一个版本的代码中,我们仍然有一些mul2的缓存问题;预取仍然不起作用。但是如果没有转置矩阵,这是无法解决的。也许缓存预取单元会变得更聪明来识别模式,那么就不需要额外的改变了。不过,以一个 2.66 GHz 处理器上的单线程程序而言,3.19 GFLOPS 并不差。
我们在矩阵乘法的例子中优化的是被加载cache line的使用。cache line的所有字节总是被用到。我们只是确保它们在cache line被逐出之前被使用。这当然是一个特殊情况。
更常见的情况是,数据结构填充一个或多个缓存行,而程序在任何时候只使用几个成员。在图3.11中,我们已经看到了大size结构在只有一些成员被用到时的影响。
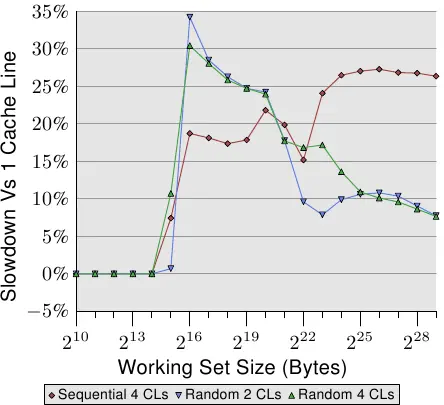
图6.2显示了使用现在已熟知的程序执行另一组基准测试的结果。这次添加了相同列表元素的两个值。一种情况下,两个元素都在相同的缓存行中;另一种情况下,一个元素在列表元素的第一个缓存行中,第二个在最后一个缓存行中。该图显示了我们正在经历的性能衰减。
不出所料,在所有情况下,如果工作集能放进 L1d,都不会有负面影响。一旦L1d不再足够,就会通过在进程中使用两条cache line而不是一条来支付损失。红线显示了列表在内存中顺序排列时的数据。我们看到通常的两步模式:当L2缓存足够时,大约有17%的损失,当必须使用主存时,大约有27%的损失。
在随机内存访问的情况下,相对的数据看起来有点不同。适合L2的工作集的性能衰减在25%到35%之间。再往后,它下降到大约10%。这不是因为损失变得更小,而是因为实际的内存访问变得不成比例地昂贵。数据还显示,在某些情况下,元素之间的距离确实很重要。Random 4 CLs曲线显示了更高的损失,因为使用了第一条和第四条cache line。
查看与cache line相比较的数据结构布局的一个简单方法是使用pahole程序(参见4)。这个程序检查二进制中定义的数据结构。取一个包含这个定义的程序:
1 | struct foo { |
当在64位机器上编译时,pa-hole的输出包含(除其他外)图6.3所示的输出。这个输出告诉我们很多。首先,它显示数据结构使用了不止一条cache line。该工具假设当前使用的处理器的cache line大小,但是这个值可以使用命令行参数覆盖。特别是在结构的大小刚刚超过cache line的限制,并且分配了许多这种类型的对象的情况下,寻找一种压缩该结构体的方法是有意义的。也许一些元素可以有更小的类型,或者一些字段实际上是标志,可以用单个位来表示。
1 | struct foo { |
在这个例子中,压缩很容易,程序也暗示了这一点。输出显示在第一个元素后面有一个四个字节的洞。这个洞是由结构体对齐要求和填充元素造成的。很容易看到元素b,它的大小为四个字节(由行尾的4表示),完全适合间隙(gap)。在这种情况下,结果是间隙(gap)不再存在,数据结构塞得进一条cache line。pahole工具可以自己执行这种结构体最佳化。如果使用--reorganization参数,并在命令行的末尾添加结构体名称,工具的输出就是最佳化的结构和使用的cache line。除了移动元素来填充间隙之外,该工具还可以优化bit 字段,并合并填充(padding)和洞。有关更多详细信息,请参见4。
当然,拥有一个足够大的洞来容纳末尾元素是理想的情况。为了使这种选项有用,需要对象本身与缓存行对齐。我们稍后会谈到这一点。
pahole 输出也能够轻易看出元素是否必须被重新排列,以令那些一起用到的元素也会被储存在一起。使用 pahole 工具,很容易就能够确定哪些元素要在同个cache行,而不是必须在重新排列元素时才能达成。这并不是一个自动的过程,但这个工具能帮助很多。
各个结构元素的位置、以及它们被使用的方式也很重要。如同我们已经在 3.5.2 节看到的,晚到cache line的关键word的程序效能是很糟的。这表示一位程序开发者应该总是遵循下列两条原则:
- 总是将最可能为关键word的结构元素移到结构的开头。
- 当访问数据结构时,访问顺序不受情况决定,按照结构中定义的顺序访问元素
以小结构而言,这表示元素应该以它们可能被存取的顺序排列。这必须以灵活的方式处理,以允许其它像是填充,洞之类的优化也能被使用。对于较大的资料结构,每个cache line大小的区块应该遵循这些原则来排列。
但是,如果对象本身没有按预期对齐,就不值得花时间来重新排列它。对象的对齐由数据类型的对齐要求决定。每个基本类型都有自己的对齐要求。对于结构体类型,其任何元素中的最大对齐要求决定了结构体的对齐。这几乎总是小于cache line大小。这意味着即使结构体的成员被排列成塞得进同一个cache line,分配的对象也可能没有与cache line大小匹配的对齐方式。有两种方法可以确保对象具有在设计结构布局时使用的对齐:
方法一 可以根据明确的对齐要求分配对象。对于动态分配,调用malloc只会以相符于最严格的标准类型(通常是long Double)的对齐来分配对象。不过,使用 posix_memalign 请求较高的对齐也是可能的。
1 |
|
该函数将指向新分配内存的指针存储在memptr指向的指针变量中。内存块的大小为size字节,并在align字节边界上对齐。
对于编译器分配的对象(在 .data、.bss 等和堆栈上),可以使用变量属性(attribute):
1 | struct strtype variable |
在这个情况下,不管 strtype 结构的对齐需求为何,variable 都会在 64 byte边界上对齐。这也适用于全局变量和自动变量。
对于数组,这种方法并不像人们期望的那样工作。除非每个数组元素的大小是对齐值的倍数,否则只有数组的第一个元素会对齐。这也意味着每个变量都必须得到适当的标注。posix_memalign的使用也不是完全免费的,因为对齐要求通常会导致碎片和/或更高的内存消耗。
方法二 可以使用type属性更改用户定义类型的对齐要求:
1 | struct strtype { |
这将导致编译器以适当的对齐方式分配所有对象,包括数组。不过,程序员必须注意为动态分配的对象请求适当的对齐方式。这里必须再次使用posix_memalign。使用gcc提供的对齐运算符并将值作为第二个参数传递给posix_memalign很容易。
本节前面提到的多媒体扩展几乎总是要求内存访问对齐。即,对于16字节的内存访问,地址应该是16字节对齐的。x86和x86-64处理器具有特殊的内存操作变体,可以处理未对齐的访问,但速度较慢。对于大多数需要对所有内存访问进行完全对齐的RISC架构来说,这种硬对齐要求并不是什么新鲜事。即使架构支持未对齐的访问,这有时也比使用适当的对齐慢,特别是如果不对齐导致加载或存储使用两条cache line 而不是一条。
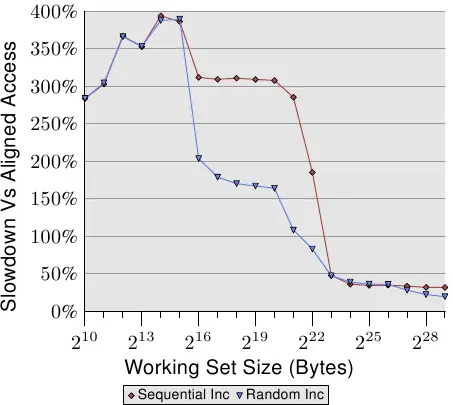
图 6.4 显示非对齐memory访问的影响。现在众所周知的测试是在访问内存(顺序或随机)时增加数据元素的,一次是对齐的列表元素,一次是故意不对齐的元素。该图显示了程序由于未对齐访问而导致的减速。顺序访问情况的影响比随机情况更显著,因为在后一种情况下,未对齐访问的成本被通常较高的内存访问成本部分隐藏。在顺序情况下,对于适合L2缓存的工作集大小,减速约为300%。这可以用L1缓存的有效性降低来解释。一些递增操作现在触及两条cache line,现在开始对列表元素的工作通常需要读取两条cache line。L1和L2之间的连接太拥挤了。
对于非常大的工作集,未对齐访问的影响仍然是20%到30%——考虑到这些规模的工作集的对齐访问时间很长,这是一个很大的影响。这张图应该表明对齐必须认真对待。即使架构支持未对齐访问,这也不能被视为“它们和对齐访问一样好”。
但是,这些对齐要求会产生一些影响。如果自动变量有对齐要求,编译器必须确保在所有情况下都满足它。这并不简单,因为编译器无法控制调用点(call site)与它们处理堆栈的方式。这个问题可以通过两种方式处理:
- 产生的程序主动地对齐堆栈,必要时插入间隔。这需要程序检查对齐、建立对齐、并在之后还原对齐。
- 要求所有的调用点都将堆栈对齐。
所有常用的应用程序二进制接口(ABI)都遵循第二条路线。如果调用者违反规则并且需要在被调用者中对齐,程序可能会失败。不过,保持对齐不变并不是免费的。
函数中使用的堆栈帧的大小不一定是对齐的倍数。这意味着如果从该堆栈帧调用其他函数,则需要填充。最大的区别在于,在大多数情况下,编译器知道堆栈帧的大小,因此,它知道如何调整堆栈指针以确保从该堆栈帧调用的任何函数的对齐。事实上,大多数编译器会简单地将堆栈帧大小四舍五入并完成它。
如果使用可变长度数组(VLA)或alloca,这种简单方法是不可能处理对齐的。在这种情况下,堆栈帧的总大小只有在运行时才知道。在这种情况下,可能需要主动对齐控制,从而使生成的代码(稍微)变慢。
在某些架构上,只有多媒体扩展需要严格对齐;这些架构上的堆栈总是针对正常数据类型进行最小对齐,通常分别针对32位和64位架构进行4或8字节对齐。在这些系统上,强制对齐会产生不必要的成本。这意味着,在这种情况下,如果我们知道它永远不会被依赖,我们可能希望摆脱严格的对齐要求。没有多媒体操作的尾函数(那些不调用其他函数的函数)不需要对齐。只调用不需要对齐的函数的函数也不用。如果可以确定足够大的函数集,程序可能希望放宽对齐要求。对于x86二进制文件,gcc支持宽松的堆栈对齐要求:-mpreferred-stack-boundary=2。
若是这个选项(option)的值为 ,堆栈对齐需求将会被设为 byte。所以,若是使用 2 为值,堆栈对齐需求就被从预设值(16 byte)降低成只有4byte。在大多情况下,这表示不需额外的对齐操作,因为普通的堆栈推入(push)与弹出(pop)操作无论如何都是在4 byte边界上操作的。这个机器特定的选项能够帮忙减少程序大小,也能够提升执行速度。但它无法被套用到许多其它的架构上。即使对于x86-64,一般来说也不适用,因为 x86-64 ABI 要求在 SSE 暂存器中传递浮点数参数,而 SSE 指令需要完整的 16 byte对齐。然而,只要能够使用这个选项,就能造成明显的差别。
结构元素的有效放置和对齐并不是影响缓存效率的数据结构的唯一方面。如果使用结构数组,整个结构定义会影响性能。回想一下图 3.11 的结果:在这种情况下,我们在数组元素中增加了未使用的数据量。结果是预取的效率越来越低,对于大型数据集,程序变得不那么有效。
对于大型工作集,尽可能使用可用的缓存很重要。为了实现这一点,可能需要重新排列数据结构。虽然程序员更容易将概念上属于同一数据结构的所有数据放在一起,但这可能不是获得最大性能的最佳方法。假设我们有如下数据结构:
1 | struct order { |
进一步假设这些记录存储在一个大数组中,一个经常运行的作业将所有未偿账单的预期付款加起来。在这种情况下,用于buyer和buyer_id字段的内存被不必要地加载到缓存中。从图3.11中的数据来看,程序的性能将比它可能的性能差5倍。
最好将order数据结构分成两块,将前两个字段存储在一个结构中,将其他字段存储在其他地方。这种变化肯定会增加程序的复杂性,但性能提升可能会证明这种成本是合理的。
最后,让我们考虑另一种缓存使用优化,虽然它也适用于其他缓存,但主要体现在L1d访问中。如图3.8所示,缓存关联性的增加有利于正常的操作。缓存越大,关联性通常越高。L1d cache太大,以致于无法为全关联式,但又没有足够大到要拥有跟 L2 cache一样的关联度。若是工作集中的许多对象属于相同的cache集,这可能会是个问题。如果这导致由于过于使用一组集合而造成逐出,即使大多cache都没被用到,程序还是可能会受到延迟。这些cache错失有时被称为冲突性丢失(conflict miss)。由于 L1d 定址使用虚拟地址,这实际上是能够受程序开发者控制的。如果一起被用到的变数也储存在一块儿,那么它们落入同一集合的可能性就会最小化。图 6.5 显示了问题发生的速度。
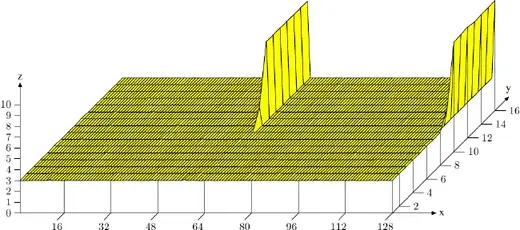
在这张图中,现在熟悉的、使用 NPAD=15 的 Follow[3] 。测试是以特殊的配置来量测的。X 轴是两个列表元素之间的距离,以空列表元素为单位量测。换句话说,距离为 2 代表下一个元素的地址是在前一个元素的 128 byte之后。所有元素都以相同的距离在虚拟memory空间中摆放。Y 轴显示列表的总长度。仅会使用 1 至 16 个元素,代表工作集总大小为 64 至 1024 byte。Z 轴显示寻访每个列表元素所需的平均周期数。
图中显示的结果并不令人惊讶。如果使用很少的元素,所有数据都适合L1d,每个列表元素的访问时间只有3个周期。几乎所有列表元素的排列都是如此:虚拟地址被很好地映射到L1d插槽,几乎没有冲突。有两个(在这张图中)特殊的距离值,情况不同。如果距离是4096字节的倍数(即64个元素的距离),并且列表的长度大于8,则每个列表元素的平均周期数急剧增加。在这种情况下,所有条目都在同一个集合中,一旦列表长度大于关联性,条目就会从L1d流出,并且必须在下一轮从L2重新读取。这导致每个列表元素大约10个周期的成本。
通过这张图,我们可以确定所使用的处理器有一个关联性为8的L1d缓存,总大小为32kB。这意味着如果有必要,可以使用测试来确定这些值。对于L2缓存,可以测量同样的影响,但是,这里,它更复杂,因为L2缓存使用物理地址进行索引,而且它要大得多。
程序员希望将这些数据视为集合关联性是值得关注的指标。在现实世界中,将数据布局在2次方的边界上经常发生,但这正是很容易导致上述影响和性能下降的情况。未对齐的访问会增加冲突未命中的可能性,因为每次访问都可能需要额外的缓存行。

如果执行这种优化,另一种相关的优化也是可能的。AMD的处理器至少将L1d实现为几个单独的bank。L1d每个周期可以接收两个数据字,但前提是两个字都存储在不同的bank或具有相同索引的bank中。bank地址被编码为虚拟地址的低位,如图6.6所示。如果一起使用的变量也一起存储,那么它们在不同bank或具有相同索引的同一bank中的可能性很高。
优化一级指令缓存访问
准备有效使用 L1i 的程序码需要与有效使用 L1d 类似的技术。不过,问题是,程序开发者通常不会直接影响 L1i 的使用方式,除非他在汇编程序中编写代码,否则程序语法通常不会直接影响L1i的使用方式。若是使用编译器,程序开发者能够透过引导编译器建立更好的程序布局,来间接地决定 L1i 的使用。
代码的优点是跳转之间是线性的。在这些时期,处理器可以有效地预取内存。跳转打破这个美好的想像,因为:
- 跳跃目标可能不是静态确定的;
- 即使它是静态的,如果它错过了所有缓存,内存获取也可能需要很长时间。
这些问题造成执行中的停顿,可能严重地影响效能。这即是为何现今的处理器在分支预测(branch prediction,BP)上费尽心思的原因。高度特制化的 BP 单元试著尽可能远在跳跃之前确定跳跃的目标,使得处理器能够开始将新的位置的指令载入到cache中。它们使用静态与动态规则、而且越来越擅于判定执行中的模式。
尽快将数据放入缓存对于指令缓存来说更加重要。如第3.1节所述,指令必须在执行之前进行解码,为了加快速度(在x86和x86-64上很重要),指令实际上以解码形式缓存,而不是从内存中读取的字节/字形式。
为了实现最佳的L1i使用,程序员至少应该注意代码生成的以下方面:
- 尽可能减少代码占用。这必须与循环展开和内联等优化相平衡。
- 代码执行应该是线性的,没有气泡[4]。
- 在有意义的时候对齐代码。
我们现在将研究一些可用于帮助根据这些方面优化程序的编译器技术。
编译器可以选择启用优化级别;也可以单独启用特定的优化。许多在高优化级别启用的优化(gcc的-O2和-O3)处理循环优化和函数内联。一般来说,这些都是很好的选择。如果以这些方式优化的代码占程序总执行时间的很大一部分,则可以提高整体性能。特别是函数内联,允许编译器在同一时间优化更大的代码块,这反过来又可以生成更好地开发处理器管道架构的机器代码。当程序的较大部分可以被视为单个单元时,代码和数据的处理(通过死代码消除或值范围传播等)效果更好。
较大的代码大小意味着对L1i(以及L2和更高级别)缓存的压力更大。这可能会导致性能下降。较小的代码可能会更快。幸运的是,gcc有一个优化选项来指定这一点。如果使用-os,编译器将针对代码大小进行优化。已知会增加程序大小的最佳化会被关掉。使用此选项通常会产生令人惊讶的结果。特别是如果编译器不能真正利用循环展开和内联,则此选项是一个巨大的胜利。
内联也可以单独控制。编译器有指导内联的启发式和限制;这些限制可以由程序员控制。-finnline-limited选项指定函数必须有多大才能被认为太大而无法内联。如果一个函数在多个地方被调用,在所有地方内联它会导致代码大小爆炸。但是还有更多。假设一个函数inlcand在两个函数f1和f2中被调用。函数f1和f2本身是按顺序调用的。
| |
表6.3显示了在两个函数中没有内联和内联的情况下生成的代码。如果函数inlcand在f1和f2中都被内联,则生成的代码的总大小为 size f1 + size f2 + size inlcand。如果没有发生内联,则总大小减少 size inlcand。如果f1和f2相继调用,则需要更多的L1i和L2缓存。另外:如果inlcand 没有内联,代码可能仍在L1i中,并且不必再次解码。另外:分支预测单元可能会更好地预测跳转,因为它已经看到了代码。如果编译器默认的内联函数大小上限不适合程序,则应该降低它。
然而,在某些情况下,内联总是有意义的。如果一个函数只被调用一次,它还不如被内联。这给了编译器执行更多优化的机会(比如值范围传播,这可能会显著改进代码)。这种内联可能会受到选择限制的阻碍。对于这种情况,gcc有一个选项来指定一个函数总是内联的。添加always_inline函数属性会指示编译器完全按照名称所暗示的去做。
在相同的上下文中,如果一个函数足够小,但永远不应该内联,则可以使用noinline函数属性。如果经常从不同的地方调用它们,即使对于小函数,使用此属性也有意义。如果L1i内容可以重用,并且总体占用空间减少,这通常可以弥补额外函数调用的额外成本。分支预测单元现在非常好。如果内联可以导致更积极的优化,事情看起来就不同了。这必须根据具体情况来决定。
如果总是使用内联代码,always_inline属性工作得很好。但是如果不是这样呢?如果内联函数只是偶尔调用怎么办?
1 | void fct(void) { |
为这样的代码序列生成的代码通常与源的结构相匹配。这意味着首先是代码块A,然后是条件跳转,如果条件评估为false,则向前跳转。接下来是为内联inlfct生成的代码,最后是代码块C。这看起来很合理,但有一个问题。
如果条件经常为假,则执行不是线性的。中间有一大块未使用的代码,这不仅由于预取而污染L1i,还会导致分支预测问题。如果分支预测是错误的,条件表达式可能非常无效。
这是一个普遍的问题,而不是只内联函数。每当使用条件执行并且它是不平衡的(即,表达式通常导致一个结果而不是另一个结果)时,就有可能出现错误的静态分支预测,从而在管道中产生气泡。这可以通过告诉编译器将不太经常执行的代码移出主代码路径来防止。在这种情况下,为if语句生成的条件分支将跳转到顺序错误的地方,如下图所示。
上面的部分代表简单的代码布局。如果区域B,例如从上面的内联函数inlfct生成的,因为条件I跳过它而经常不执行,处理器的预取将拉入包含很少使用的块B的缓存行。使用块重新排序可以改变这一点,结果可以在图的下部看到。经常执行的代码在内存中是线性的,而很少执行的代码被移动到不影响预取和L1i效率的地方。
gcc提供了两种方法来实现这一点。首先,编译器可以在重新编译代码时考虑配置输出,并根据配置文件布局代码块。我们将在第7节中看到这是如何工作的。第二种方法是通过显式分支预测。gcc识别__builtin_expect:
1 | long __builtin_expect(long EXP, long C); |
这个构造告诉编译器表达式EXP很可能具有值C。返回值是EXP。__builtin_expect用于条件表达式。在几乎所有情况下,它都会在布尔表达式的上下文中使用,在这种情况下,定义两个辅助宏要方便得多:
1 |
然后可以将这些宏用作
1 | if (likely(a > 1)) |
如果程序员使用这些宏,然后使用-freorder-block优化选项,gcc将重新排序块,如上图所示。此选项使用-O2启用,但对-O禁用。还有另一个gcc选项来重新排序块-freorder-blocks-and-partition,但它的有用性有限,因为它不适用于异常处理。
至少在某些处理器上,小循环还有另一个很大的优势。英特尔酷睿2前端有一个特殊的功能,叫做循环流检测器(LSD)。如果一个循环不超过18条指令(没有一条是对子例程的调用),最多只需要4个16字节的解码器提取,最多有4个分支指令,并且执行超过64次,那么循环有时会被锁定在指令队列中,因此在再次使用循环时可以更快地使用。例如,这适用于通过外循环多次输入的小型内部循环。即使没有这种专门的硬件,紧凑的循环也有优势。
内联不是L1i优化的唯一方面。另一个方面是对齐,就像数据一样。有明显的区别:代码是一个主要是线性的blob,不能任意放置在地址空间中,也不能在编译器生成代码时直接受到程序员的影响。虽然程序员可以控制某些方面。将每条指令对齐没有任何意义。目标是让指令流是顺序的。所以对齐只在战略位置有意义。要决定在哪里添加对齐,有必要了解优势是什么。在缓存线的开头有一条指令[5]意味着缓存线的预取最大化。对于指令来说,这也意味着解码器更有效。很容易看出,如果执行缓存线末尾的指令,处理器必须准备好读取新的缓存线并对指令进行解码。有些事情可能会出错(例如缓存线未命中),这意味着平均而言,缓存线末尾的指令执行效率不如开头的指令。
将此与后续推论相结合,即如果控制只是转移到有问题的指令(因此预取无效),问题最严重,我们得出最终结论,代码对齐最有用的地方:
- 在函数的开头;
- 在仅会通过跳跃到达的基础区块的开头;
- 在某种程度上,在循环的开始。
在前两种情况下,对齐成本很低。执行在新位置继续,如果我们选择它在缓存行的开头,我们会优化预取和解码。[6]。编译器通过插入一系列非操作指令来填补对齐代码造成的空白来实现这种对齐。这种“死代码”占用一点空间,但通常不会损害性能。
第三种情况略有不同:对齐每个循环的开始可能会产生性能问题。问题是循环的开始通常会按顺序跟随其他代码。如果情况不是很幸运,前一条指令和对齐的循环开始之间会有一个间隙。与前两种情况不同,这个间隙不能完全消失。在前一条指令执行后,必须执行循环中的第一条指令。这意味着,在前一条指令之后,要么必须有许多无操作指令来填补空白,要么必须无条件跳转到循环的开始。这两种可能性都是免费的。特别是如果循环本身不经常执行,无操作或跳转可能会花费不止一个通过对齐循环节省的成本。
程序员可以通过三种方式影响代码的对齐。显然地,若是程序是以汇编语言撰写,其中的函数与所有的指令都能够被明确地对齐。汇编器为所有架构提供了.align 伪操作来做到这一点。对于高级语言,必须告知编译器对齐要求。与数据类型和变量不同,这在源代码中是不可能的。相反,使用编译器选项:-falign-functions=N。这个选项命令编译器将所有函数对齐到下一个大于 N 的二的幂次的边界。这表示会产生一个至多 N byte的间隔。对小函数而言,使用一个很大的 N 值是个浪费。对于很少执行的代码也是如此。后者在包含流行和不太流行接口的库中经常发生。明智地选择选项值可以通过避免对齐来加快速度或节省内存。通过使用一个作为N的值或使用-fno-align-functions选项来关闭所有对齐。
上面第二种情况的对齐方式(基本块的开头没有按顺序到达)可以用不同的选项来控制:-falign-jumps=N。所有其它的细节都相同,关于浪费memory的警告也同样适用。
第三种情况也有它自己的选项:-falign-loops=N。再一次,同样的细节与警告都适用。除了这里,如前所述,对齐是以运行时成本为代价的,因为如果顺序到达对齐的地址,则必须执行无操作或跳转指令。
gcc 还知道一个用来控制对齐的选项,在这里提起它仅是为了完整起见。-falign-labels 对齐了程序中的每个单一标签(基本上是每个基础区块的开头)。除了一些例外状况之外,这都会让程序变慢,因而不该被使用。
优化二级与更高级缓存访问
关于1级缓存优化的所有内容也适用于2级和更高级别的缓存访问。最后一级缓存还有两个额外的方面:
- 缓存未命中总是非常昂贵的。虽然L1未命中(希望)经常命中L2和更高级别的缓存,从而限制了惩罚,但显然最后一级缓存没有回退。
- L2及更高版本的缓存通常由多个内核和/或超线程共享。因此,每个执行单元可用的有效缓存大小通常小于总缓存大小。
为了避免缓存未命中的高成本,工作集大小应该与缓存大小匹配。如果数据只需要一次,这显然是不必要的,因为缓存无论如何都是无效的。我们谈论的是多次需要数据集的工作负载。在这种情况下,使用太大而无法放入缓存的工作集会产生大量缓存未命中,即使成功执行预取,也会减慢程序的速度。
即使数据集太大,程序也必须执行它的工作。程序员的工作是以最小化缓存miss的方式完成这项工作。对于最后一级缓存,可能是(就像L1缓存一样)在更小的部分上工作。这与表 6.2 的优化矩阵乘法非常相似。然而,一个区别是,对于最后一级缓存,要处理的数据块可以更大。如果也需要L1优化,代码会变得更加复杂。想象一个矩阵乘法,其数据集(两个输入矩阵和输出矩阵)无法同时进入最后一级缓存。在这种情况下,同时优化L1和最后一级缓存访问可能是合适的。
L1高速缓存线大小在许多代处理器中通常是恒定的;即使不是,差异也很小。仅仅假设较大的大小没有什么大问题。在高速缓存大小较小的处理器上,将使用两条或多条高速缓存线而不是一条。无论如何,硬编码高速缓存线大小并为此优化代码是合理的。
对于更高级别的缓存,如果程序应该是通用的,情况就不是这样了。这些缓存的大小可以有很大的不同。8个或更多的因素并不罕见。不可能假设较大的缓存大小为默认值,因为这意味着代码在所有机器上的性能都很差,除了那些缓存最大的机器。相反的选择也很糟糕:假设最小的缓存意味着丢弃87%或更多的缓存。这很糟糕;正如我们从图3.14中看到的,使用大型缓存会对程序的速度产生巨大影响。
这意味着代码必须根据缓存行大小动态调整自身。这是对程序的优化。这里我们只能说程序员应该正确计算程序的需求。不仅需要数据集本身,更高级别的缓存也用于其他目的;例如,所有执行的指令都是从缓存加载的。如果使用库函数,这种缓存使用量可能会增加很多。这些库函数可能还需要自己的数据,这进一步减少了可用内存。
一旦我们有了内存需求的公式,我们就可以将其与缓存大小进行比较。如前所述,缓存可能与多个其他内核共享。目前[7],在没有硬编码知识的情况下获得正确信息的唯一方法是通过/sys文件系统。在表5.2中,我们已经看到了内核发布的关于硬件的内容。程序必须在目录查找: /sys/devices/system/cpu/cpu*/cache。
对于最后一级缓存。这可以通过该目录下 level 文件中的最高数值来识别。当目录被识别时,程序应该读取该目录中 size 文件的内容,并将数值除以shared_cpu_map 文件中位掩码的二进制数字值。
以这种方式计算的值是一个安全的下限。有时,程序更了解其他线程或进程的行为。如果这些线程被安排在共享缓存的核心或超线程上,并且已知缓存使用不会耗尽其在总缓存大小中的比例,那么计算的限制可能太低而不是最佳的。是否应该使用超过公平份额实际上取决于情况。程序编写者必须做出选择或必须允许用户做出决定。
优化TLB使用
TLB使用有两种优化。第一种优化是减少程序必须使用的页数。这会自动导致更少的TLB未命中。第二种优化是通过减少必须分配的高级目录表的数量来降低TLB查找的成本。更少的表意味着使用更少的内存,这可能会导致目录查找的更高缓存命中率。
第一个优化与最小化分页错误密切相关。我们将在第7.5节中详细讨论这个主题。虽然分页错误通常是一次性成本,但TLB未命中是一种永久的惩罚,因为TLB缓存通常很小,而且经常刷新。分页错误比TLB未命中贵几个数量级,但是,如果程序运行时间足够长,并且程序的某些部分执行得足够频繁,TLB未命中的成本甚至可能超过分页错误成本。因此,不仅要从分页错误的角度看待分页优化,还要从TLB未命中的角度看待分页优化。不同之处在于,虽然分页错误优化只需要对代码和数据进行分页范围的分组,但TLB优化要求在任何时候都尽可能少地使用TLB条目。
第二个TLB优化更难控制。必须使用的页面目录的数量取决于进程虚拟地址空间中使用的地址范围的分布。地址空间中位置的广泛变化意味着更多的目录。复杂的是地址空间布局随机化(ASLR)会导致这些情况。堆栈、DSO、堆和可能的可执行文件的加载地址在运行时是随机的,以防止机器的攻击者猜测函数或变量的地址。
只有当最高性能是关键时,ASLR才应该被关闭。额外目录的成本足够低,除了少数极端情况之外,其他情况下都不需要这个步骤。内核可以在任何时候执行的一种可能的优化是确保单个映射不跨越两个目录之间的地址空间边界。这将以最小的方式限制ASLR,但不足以大大削弱它。
程序开发者直接受此影响的唯一方式是在明确请求一个定址空间区域的时候。这会在以 MAP_FIXED 使用 mmap 的时候发生。以这种方式分配定址空间区域非常危险,人们几乎不会这么做。如果程序开发者使用上述方法且允许自由选取地址,则他们应该要知道最后一阶分页目录的边界,及适当挑选所请求的地址。
预取
预取的目的是隐藏内存访问的延迟。当今处理器的命令流水线和乱序(out-of-order,简称OOO)执行能力可以隐藏一些延迟,但充其量只能用于访问缓存的访问。为了掩盖主存访问的延迟,命令队列必须非常长。一些没有OOO的处理器试图通过增加内核数量来弥补,但这是一笔糟糕的交易,除非所有正在使用的代码都并行化。预取可以进一步帮助隐藏延迟。处理器自行执行预取,由某些事件触发(硬件预取)或程序明确请求(软件预取)。
硬件预取
CPU启动硬件预取的触发,通常是以某种模式出现的两个或多个缓存未命中的序列。这些缓存未命中可能在缓存行的之前或之后。在旧的实现中,只识别相邻缓存行的缓存未命中。对于现代硬件,步幅也被识别,这意味着跳过固定数量的缓存行被识别为一种模式并得到适当的处理。
如果每一次缓存未命中都会触发一次硬件预取,这将对性能不利。随机内存访问模式,例如对全局变量的访问,非常常见,由此产生的预取将大大浪费FSB带宽。这就是为什么要启动预取,至少需要两次缓存未命中。今天的处理器都期望有不止一个内存访问流。处理器试图自动将每个缓存未命中分配给这样的流,如果达到阈值,则开始硬件预取。今天的CPU可以跟踪8到16个单独的流以用于更高级别的缓存。
负责模式识别的单元与各自的缓存相关联。L1d和L1i缓存可以有一个预取单元。L2缓存和更高版本很可能有一个预取单元。L2和更高版本的预取单元与使用相同缓存的所有其他内核和超线程共享。因此,8到16个单独流的数量很快就减少了。
预取有一个很大的缺点:它不能跨越分页边界。当人们意识到CPU支持需求分页时,原因应该是显而易见的。如果允许预取器跨越分页边界,访问可能会触发操作系统事件以使分页可用。这本身可能是不好的,尤其是对性能而言。更糟糕的是预取器不知道程序或操作系统本身的语义。因此,它可能会预取在实际上永远不会被请求的分页。这意味着预取器将预取超过处理器之前以可识别的模式访问的内存区域的边界。这不仅是可能,而且是非常可能。如果处理器–作为预取的副作用–触发了对这样一个分页的请求,操作系统甚至可能会在这种请求永远也不会发生时完全扔掉它的追踪纪录。
因此,重要的是要认识到,不管预取器在预测模式方面有多好,除非程序明确预取或从新分页读取,否则它将在分页边界处经历缓存未命中。这是优化数据布局的另一个原因,如第6.2节所述,通过将不相关的数据排除在外来最小化缓存污染。
由于这个分页限制,今天的处理器没有非常复杂的逻辑来识别预取模式。以仍占主导地位的 4k 分页大小而言,有意义的也就这么多。多年来,识别步幅的地址范围有所增加,但超越今天经常使用的512字节窗口可能没有多大意义。目前预取单元无法识别非线性访问模式。这种模式很可能是真正随机的,或者至少完全不重复的,尝试识别它们是没有意义的。
如果不小心触发了硬件预取,你只能做这么多。一种可能是尝试检测这个问题,并稍微改变一下数据与/或代码布局。这可能很难。可能会有特殊的本地化解决方案,例如在x86和x86-64处理器上使用ud2指令[8]。这个无法自己执行的指令是在一条间接的跳跃指令后被使用;它被作为指令获取器(fetcher)的一个信号使用,表示处理器不应浪费精力解码接下来的memory,因为执行将会在一个不同的位置继续。不过,这是个非常特殊的情况。在大部分情况下,必须要忍受这个问题。
可以完全或部分禁用整个处理器的硬件预取。在Intel处理器上,为此使用模型特定寄存器(MSR)(IA32 MISC ENABLE,许多处理器上为 bit 9;bit 19 仅禁用相邻的缓存行预取)。在大多数情况下,这必须在内核中发生,因为它是特权操作。若是数据分析显示,执行于系统上的一个重要的应用程序因硬件cache而遭受带宽占用和缓存过早驱逐,使用这个 MSR 是一种可能性。
软件预取
硬件预取的优势在于不必调整程序。缺点如同方才描述的,存取模式必须很直观,而且预取无法横跨分页边界进行。因为这些原因,我们现在有更多可能性,软件预取它们之中最重要的。软件预取不需借由插入特殊的指令来修改原始码。某些编译器支援编译指示(pragma)以或多或少地自动插入预取指令。 在 x86 和 x86-64,intrinsic 函式会由编译器产生特殊的指令:
1 |
|
程序可以在程序中的任何指针上使用_mm_prefetch intrinsic 函式。大多数处理器(当然是所有x86和x86-64处理器)忽略了无效指针导致的错误,这使得程序员的生活变得非常容易。如果传递的指针引用有效内存,预取单元将被命令将数据加载到缓存中,并在必要时驱逐其他数据。不必要的预取应该明确避免,因为这可能会降低缓存的有效性,并消耗内存带宽(在被逐出的cache行是脏的情况下,可能需要两个cache行)。
要与_mm_prefetch 内在函数一起使用的不同提示(hint)是由具体实现定义的。这意味着每个处理器版本可以(稍微)不同地实现它们。 通常可以说,对于包含缓存,_MM_HINT_T0 将数据提取到所有级别的缓存中,对于独占缓存,则提取到最低级别的缓存中。如果数据项在更高级别的缓存中,则将其加载到L1d中。_MM_HINT_T1 提示将数据拉入L2而不是L1d。如果有L3缓存,则 _MM_HINT_T2提示可以对其执行类似的操作。不过,这些都是细节,具体说明很弱,需要针对实际使用的处理器进行验证。一般来说,如果要立即使用数据,使用 _MM_HINT_T0 是正确的做法。当然,这需要L1d缓存大小足够大,以容纳所有预取的数据。如果立即使用的工作集的大小太大,那么将所有内容预取到L1d中是一个坏主意,应该使用另外两个提示。
第四种提示,_MM_HINT_NTA,允许告诉处理器特别处理预取的高速缓存行。NTA代表非暂存对齐(non-temporal aligned),我们已经在第6.1节中解释过了。程序告诉处理器,应该尽可能避免用这些数据污染高速缓存,因为这些数据只使用了很短的时间。因此,对于包容性高速缓存,处理器可以在加载时避免将数据读入较低级别的高速缓存。当数据从L1d中被逐出时,数据不需要被推入L2或更高级别,而是可以直接写入内存。如果给出这个提示,处理器设计者可能还可以部署其他技巧。程序员必须小心使用这个提示:如果立即工作集大小太大,并且强制逐出使用NTA提示加载的高速缓存行,则将从内存中重新加载。

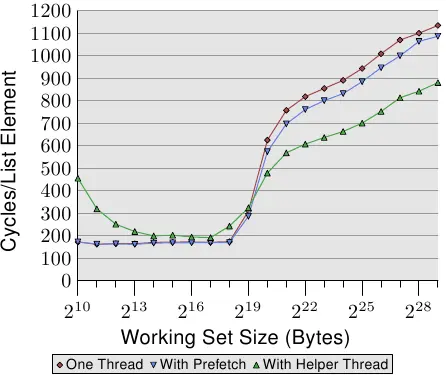
图6.7显示了使用现在熟知的指针追逐框架(pointer chasing framework)的测试结果。列表在内存中随机排列。与之前测试的不同之处在于,程序实际上在每个列表节点上花费了一些时间(大约160个周期)。正如我们从图3.15中的数据中了解到的,一旦工作集大小大于最后一级缓存,程序的性能就会受到严重影响。
我们现在可以尝试通过在计算之前发出预取请求来改善这种情况。也就是说,在每一轮循环中,我们预取一个新元素。列表中预取节点和当前正在处理的节点之间的距离必须仔细选择。考虑到每个节点在160个周期内被处理,并且我们必须预取两个缓存行(NPAD=31),五个列表元素的距离就足够了。
图6.7中的结果表明预取确实有帮助。只要工作集大小不超过最后一级缓存的大小(机器有512kB = 219B 的 L2),数字都是相同的。预取指令不会增加可衡量的额外负担。一旦超过L2大小,预取就会节省50到60个周期,最多可达8%。使用预取不能隐藏所有的损失,但它确实有一点帮助。
AMD 在它们 Opteron 产品线的 10h 家族实现了另一个指令:prefetchw。在 Intel 这边迄今仍没有这个指令的等价物,也不能通过 intrinsic 使用。prefetchw 指令要求 CPU 将cache行预取到 L1 中,就如同其它预取指令一样。差异在于cache行会立即变成「M」状态。若是之后没有接著对cache行的写入,这将会是个不利之处。但若是有一或多次写入,它们将会被加速,因为写入操作不必改变cache状态 –– 其在cache行被预取时就被设好。这对于竞争的cache行尤为重要,其中在另一个处理器的cache中的cache行的一次普通的读取操作会先在两个cache中将状态改成「S」。
预取可能有比我们这里达到的微薄的 8% 还要更大的优势。但它是众所皆知地难以做得正确,特别是如果相同的二进制文件应该在各种机器上运行良好。CPU提供的性能计数器可以帮助编程人员分析预取。可以计数和采样的事件包括硬件预取、软件预取、有用/使用的软件预取、不同级别的缓存未命中等等。在第7.1节中,我们将介绍一些这样的事件。所有这些计数器都是机器特定的。
在分析程序时,应该首先查看缓存未命中。当有大量缓存未命中时,应该尝试为有问题的内存访问添加预取指令。这应该一次在一个地方完成。应该通过观察测量有用预取指令的性能计数器来检查每次修改的结果。如果这些计数器没有增加预取可能是错误的,它没有足够的时间从内存中加载,或者预取从缓存中驱逐仍然需要的内存。
今天的gcc能够在一种情况下自动发出预取指令。如果循环正在遍历数组,则可以使用以下选项:-fprefetch-loop-arrays
编译器将弄清楚预取是否有意义,如果有,它应该往前看多远。对于小型数组,这可能是一个缺点,如果在编译时不知道数组的大小,结果可能会更糟。gcc手册警告说,好处在很大程度上取决于代码的形式,在某些情况下,代码实际上可能运行得更慢。程序员必须小心使用此选项。
特殊的预取类型:猜测
现代处理器的OOO执行能力允许在指令不相互冲突的情况下移动指令。例如(这次使用IA-64作为示例):
1 | st8 [r4] = 12 |
这段代码在寄存器 r4 指定的地址存储12,将寄存器 r6 和 r7 的内容相加并将其存储在寄存器 r5 中。最后,它将总和存储在寄存器 r18 指定的地址。这里的重点是add指令可以在第一条 st8 指令之前执行,或者与第一条st8指令同时执行,因为没有数据依赖关系。但是如果必须加载其中一个加数会发生什么呢?
1 | st8 [r4] = 12 |
额外的 ld8 指令从寄存器 r8 指定的地址中加载值。这个加载指令和接下来的 add 指令之间有明显的数据依赖关系(这就是为什么在指令之后有 ;;)。这里的关键是新的 ld8指令——与 add 指令不同——不能移动到第一个st8 的前面。处理器在指令解码期间无法足够快地确定存储和加载是否冲突,即 r4 和 r8 是否可能具有相同的值。如果它们确实具有相同的值,st8 指令将确定加载到 r6 中的值。更糟糕的是,在载入未命中cache的情况下 ld8 还可能带来很大的延迟。IA-64架构支持这种情况的推测加载(speculative load):
1 | ld8.a r6 = [r8];; |
新的 ld8.a 和 ld8.c.clr 指令是一对的,并替换了前面代码中的 ld8 指令。ld8.a 指令是猜测式加载。该值不能直接使用,但处理器可以开始工作。当到达 ld8.c.clr指令时,内容可能已经被加载了(给定间隙中有足够数量的指令)。该指令的参数必须与 ld8.a 指令的参数匹配。如果前面的 st8 指令没有覆盖该值(即r4和 r8相同[9]),则无需做任何事情。猜测式加载完成了它的工作,加载的等待时间被隐藏。如果存储和加载发生冲突,ld8.c.clr 会从内存中重新加载该值,我们最终会得到正常的ld8 指令的语义。
猜测式加载还没有被广泛使用。但是正如这个例子所示,这是一种非常简单而有效的隐藏等待时间的方法。预取基本上是等价的,对于寄存器很少的处理器来说,猜测负载可能没有多大意义。猜测测负载有一个(有时很大的)优势,那就是直接将值加载到寄存器中,而不是缓存行中,在缓存行中,它可能会再次被逐出(例如,当线程被重新调度时)。如果可以使用猜测,就应该使用它。
辅助线程
当一个人试图使用软件预取时,他经常会遇到代码复杂性的问题。如果代码必须迭代一个数据结构(在我们的例子中是一个列表),他必须在同一个循环中实现两个独立的迭代:正常迭代完成工作,第二次迭代向前看,以使用预取。这很容易变得足够复杂,以至于很可能出错。
此外,有必要确定向前看多远。太少,内存将无法及时加载。太远,刚刚加载的数据可能会再次被驱逐。另一个问题是预取指令,尽管它们不会阻塞并等待内存加载,但需要时间。指令必须被解码,如果解码器太忙,这可能会很明显,例如,由于编写/生成的代码很好。最后,循环的代码大小增加。这降低了L1i效率。如果一个人试图通过连续发出多个预取请求来避免部分成本(以防第二次加载不依赖于第一次加载的结果),那么就会遇到未完成预取请求数量的问题。
另一种方法是完全分开执行正常操作和预取。这可以使用两个正常线程来发生。显然必须对线程进行调度,以便预取线程填充由两个线程访问的缓存。有两种特殊的解决方案值得一提:
- 在同一内核上使用超线程(参见3.3.4中的超线程)。在这种情况下,预取可以进入L2(甚至L1d)。
- 使用比SMT线程更笨的线程,SMT线程除了预取和其他简单操作什么也做不了。这是处理器制造商可能会探索的一个选项。
超线程的使用特别有趣。正如我们在3.3.4中看到的,如果超线程执行独立的代码,缓存的共享是一个问题。相反,如果一个线程被用作预取辅助线程,这不是问题。相反,这是个令人渴望的结果,因为最低层级的cache被预载。此外,由于预取线程大多处于空闲状态或等待内存,如果不必自己访问主存本身,另一个超线程的正常运行不会受到太大干扰。后者正是预取辅助线程所阻止的。
唯一棘手的部分是确保辅助线程不会运行得太远。它不能完全污染缓存,以至于再次驱逐最早的预取值。在Linux,使用futex系统调用7或使用POSIX线程同步原语(成本稍高)可以轻松完成同步。
该方法的好处可以在图6.8中看到。这与图6.7中的测试相同,只是添加了额外的结果。新测试创建了一个额外的辅助线程,该线程提前运行大约100个列表条目,并读取(不仅仅是预取)每个列表元素的所有缓存行。在这种情况下,我们每个列表元素有两个缓存行(NPAD=31,在32位机器上,缓存行大小为64字节)
这两个线程被安排在同一个核心的两个超线程上。测试机器只有一个核心,但是如果有多个核心,结果应该是差不多的。我们将在第6.4.3节中介绍的affinity函数用于将线程绑定到适当的超线程。
为了确定操作系统知道哪两个(或更多)处理器是超线程,可以使用libNUMA 的 NUMA_cpu_level_mask接口(见附录D)。
1 |
|
此接口可用于确定CPU的层次结构,因为它们通过缓存和内存连接。这里感兴趣的是对应于超线程的级别1。要在两个超线程上调度两个线程,可以使用libNUMA函数(为简洁起见,删除了错误处理):
1 | cpu_set_t self; |
执行这段代码后,我们有两个CPUbit集。self 可以用来设置当前线程的亲和性,hts中的掩码可以用来设置辅助线程的亲和性。理想情况下,这应该发生在线程创建之前。在第6.4.3节中,我们将介绍设置亲和性的接口。如果没有可用的超线程,NUMA_cpu_level_mask函数将返回1。这可以用作避免这种优化的标志。
这个基准测试的结果可能令人惊讶(也可能不是)。如果工作集适合L2,帮助线程的开销会降低10%到60%的性能(主要是在低端,再次忽略最小的工作集大小,噪音太高)。这应该是意料之中的,因为如果所有数据都已经在L2缓存中,预取帮助线程只使用系统资源而不会对执行做出贡献。
但是,一旦L2大小不够用,情况就会发生变化。预取辅助线程有助于减少大约25%的运行时间。我们仍然看到上升曲线,仅仅是因为预取的处理速度不够快。不过,主线程执行的算术运算和辅助线程的内存加载操作确实是相辅相成的。资源冲突最小,这导致了这种协同效应。
这个测试的结果应该可以转移到许多其他情况下。由于缓存污染,超线程通常没有用,在这些情况下会大放异彩,应该加以利用。附录D中引入的NUMA库使得寻找线程兄弟非常容易(参见附录中的示例)。如果库不可用,系统文件系统允许程序找到线程兄弟(参见表5.3中的thread_siblings列)。一旦这些信息可用,程序只需定义线程的安全性,然后以两种模式运行循环:正常操作和预取。预取的内存量应该取决于共享缓存的大小。在这个例子中,L2大小是相关的,程序可以使用 sysconf(_SC_LEVEL2_CACHE_SIZE)来查询大小。
是否必须限制辅助线程的进程取决于程序。一般来说,最好确保有一些同步,因为调度细节可能会导致显著的性能下降。
直接cache存取
在现代操作系统中,高速缓存未命中的一个来源是对传入数据流量的处理。现代硬件,如网络接口卡(NIC)和磁盘控制器,能够在不涉及CPU的情况下将接收到的或读取的数据直接写入内存。这对我们今天拥有的设备的性能至关重要,但也会导致问题。假设来自网络的传入数据包:操作系统必须通过查看数据包的标头来决定如何处理它。NIC将数据包放入内存,然后通知处理器到达。处理器没有机会预取数据,因为它不知道数据何时到达,甚至可能不知道数据到底会存储在哪里。结果是读取标头时高速缓存未命中。
英特尔已经在他们的芯片组和CPU中添加了技术来缓解这个问题14。这个想法是填充CPU的缓存,它将用数据包的数据通知传入的数据包。数据包的有效负载在这里并不重要,这些数据通常将由更高级别的函数处理,无论是在内核还是在用户级别。包报头用于决定必须处理数据包的方式,因此立即需要这些数据。
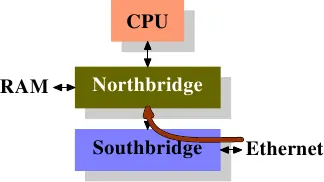
网络I/O硬件已经有DMA来写入数据包。这意味着它直接与可能集成在北桥中的内存控制器通信。内存控制器的另一面是通过FSB与处理器的接口(假设内存控制器没有集成到CPU本身)。
 DMA and DCA Executed") BeGji2TfvMGhVxGv
BeGji2TfvMGhVxGv
直接高速缓存访问(DCA)背后的想法是扩展NIC和内存控制器之间的协议。在图6.9中,第一张图显示了在具有北桥和南桥的普通机器中DMA传输的开始。NIC连接到(或是南桥的一部分)。它启动DMA访问,但提供了有关应推送到处理器缓存中的包报头的新信息。
传统的行为是,在第二步中,通过与内存的连接简单地完成DMA传输。对于使用DCA标志集的DMA传输,北桥还使用一个特殊的、新的DCA标志在FSB上发送数据。处理器总是窥探FSB,如果它识别出DCA标志,它会尝试将定向到处理器的数据加载到最低的缓存中。DCA标志实际上是一个提示;处理器可以自由地忽略它。DMA传输完成后,处理器会收到信号。
操作系统在处理数据包时,首先必须确定它是什么样的数据包。如果不忽略DCA提示,操作系统必须执行的负载来识别数据包最有可能到达缓存。将每个数据包节省的数百个周期乘以每秒可以处理的数万个数据包,这些节省加起来非常重要,尤其是在延迟方面。
少了 I/O 硬件(在这个例子中为 NIC)、晶片组与 CPU 的整合,这种最佳化是不可能的。因此,假如需要这个技术的话,确保明智地挑选平台是必要的。
多线程优化
谈到多线程,缓存使用在三个不同的方面很重要:
- 并发
- 原子性
- 带宽
这些方面也适用于多进程情况,但是,由于多个进程(大部分)是独立的,因此针对它们进行优化并不容易。可能的多进程优化是多线程场景中可用的优化的子集。因此,我们将在这里专门讨论后者。
在这种情况下,并发是指进程在一次运行多个线程时所经历的内存效应。线程的一个特性是它们都共享相同的地址空间,因此都可以访问相同的内存。在理想情况下,线程大部分时间使用的内存区域是不同的,在这种情况下,这些线程只是轻微耦合(例如,公共输入和/或输出)。如果多个线程使用相同的数据,则需要协调;这就是原子性发挥作用的时候。最后,根据机器架构,处理器可用的可用内存和处理器间总线带宽是有限的。我们将在以下部分分别处理这三个方面——当然,它们是紧密相连的。
并发优化
实际上,在本节中,我们将讨论两个不同的问题,它们实际上需要相互矛盾的优化。多线程应用程序在其某些线程中使用公共数据。正常的缓存优化要求将数据保存在一起,以便应用程序的占用空间很小,从而最大化任何时候适合缓存的内存量。
因为cache的最小单位为cache行。因此若是数据摆在一起,代表它们所占用的cache行数量较少,因此一次能cache的数据量就变多。
但是,这种方法有一个问题:如果多个线程写入一个内存位置,缓存行必须在每个相应内核的L1d中处于“E”(独占)状态。这意味着发送大量RFO消息,在最坏的情况下,每次写入访问一条。因此,正常的写入将突然变得非常昂贵。如果使用相同的内存位置,则需要同步(可能通过使用原子操作,这将在下一节中处理)。但是,当所有线程都使用不同的内存位置并且应该是独立的时,问题也很明显。
图6.10显示了这种“错误共享”的结果。测试程序(如A.3节所示)创建了许多线程,这些线程除了增加内存位置(5亿次)之外什么也不做。测量的时间是从程序开始到程序在等待最后一个线程后完成。线程被固定在单个处理器上。机器有四个P4处理器。蓝色值表示分配给每个线程的内存分配在单独的高速缓存行上的运行。红色部分是线程位置移动到一个高速缓存行时发生的惩罚。
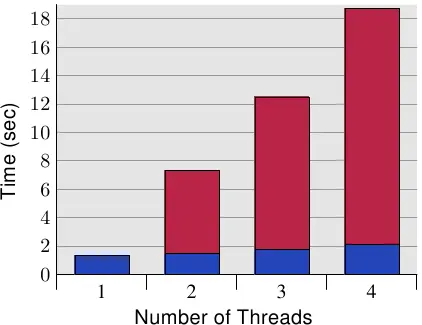
蓝色测量值(使用独立缓存行所需的时间)符合预期。该程序扩展到许多线程而不会受到惩罚。每个处理器都将其缓存行保存在自己的L1d中,并且没有带宽问题,因为不必读取太多代码或数据(事实上,它都被缓存了)。测量到的轻微增加实际上是系统噪声,可能还有一些预取效应(线程使用顺序缓存行)。
通过将每个线程使用一条高速缓存线所需的时间除以每条高速缓存线所需的时间来计算的测量开销分别为390%、734%和1,147%。这些大数字乍一看可能令人惊讶,但在考虑所需的高速缓存交互时,应该是显而易见的。高速缓存线在完成对高速缓存线的写入后立即从一个处理器的高速缓存中提取。[10]所有处理器,除了在任何给定时刻拥有高速缓存线的处理器之外,都被延迟并且不能做任何事情。每个额外的进程都只会导致更多的延迟。
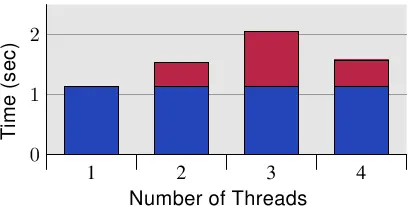
从这些测量结果可以清楚地看出,这种情况必须在程序中避免。考虑到巨大的代价,这个问题在许多情况下是显而易见的(分析至少会显示代码位置),但现代硬件存在一个陷阱。图6.11显示了在单个处理器四核机器(英特尔酷睿2 QX 6700)上运行代码时的等效测量结果。即使使用该处理器的两个独立L2,测试用例也没有显示任何可扩展性问题。多次使用相同的缓存行会有轻微的开销,但不会随着内核数量的增加而增加。如果使用多个处理器,我们当然会看到类似于图6.10中的结果。尽管多核处理器的使用越来越多,但许多机器将继续使用多个处理器,因此正确处理这种情况非常重要,这可能意味着在真实的SMP机器上测试代码。
这个问题有一个非常简单的“修复”:将每个变量放在自己的缓存行上。这就是与前面提到的优化发生冲突的地方,特别是,应用程序的占用空间会增加很多。这是不可接受的;因此有必要想出一个更智能的解决方案。
需要的是识别哪些变量一次只被一个线程使用,哪些变量永远只被一个线程使用,哪些变量有时是有争议的。对于这些场景中的每一个,不同的解决方案都是可能和有用的。区分变量的最基本标准是:它们是否曾经被写入以及这种情况发生的频率。
从不写入的变量和只初始化一次的变量基本上是常量。由于RFO消息只需要用于写入操作,因此常量可以在缓存(“S”状态)中共享。因此,这些变量不必被特殊处理;将它们组合在一起是好的。如果程序员用const正确标记变量,工具链将把变量从正常变量移至.rodata(只读数据)或.data.rel.ro(重新登录后只读)段。[11]不需要其他特殊操作。如果由于某种原因,变量不能用const正确标记,程序员可以通过将它们分配到一个特殊段来影响它们的位置。
当链接器构造最终的二进制文件时,它首先从所有输入文件中附加同名的部分;然后这些部分按照链接器脚本确定的顺序排列。这意味着,通过将所有基本上是常量但没有标记为常量的变量移动到一个特殊的部分中,程序员可以将所有这些变量组合在一起。它们之间不会有一个经常写入的变量。通过适当地对齐该部分中的第一个变量,可以保证不会发生错误共享。假设这个小例子:
1 | int foo = 1; |
如果被编译,这个输入文件定义了四个变量。有趣的是变量foo和baz,bar和xyzzy分别组合在一起。如果没有属性定义,编译器将按照源代码中定义的顺序将四个变量分配到,一个名为.data 的部分[12]。代码是这样的,变量bar和xyzzy被放置在一个名为.data.ro.部分名称.data.ro或多或少是任意的。.data的前缀。保证GNU链接器将把该部分与其他数据部分放在一起。
参考
- [1] Performance Guidelines for AMD Athlon™ 64 and AMD Opteron™ ccNUMA Multiprocessor Systems. Advanced Micro Devices, June 2006.
- [3] Vinodh Cuppu, Bruce Jacob, Brian Davis, and Trevor Mudge. High-Performance DRAMs in Workstation Environments. IEEE Transactions on Computers, 50(11):1133–1153, November 2001.
- [6] M. Dowler. Introduction to DDR-2: The DDR Memory Replacement, May 2004.
- [7] Ulrich Drepper. Futexes Are Tricky, December 2005
- [11] Joe Gebis and David Patterson. Embracing and Extending 20th-Century Instruction Set Architectures. Computer, 40(4):68–75, April 2007. 8.4
- [12] David Goldberg. What Every Computer Scientist Should Know About Floating-Point Arithmetic. ACM Computing Surveys, 23(1):5–48, March 1991.
- [14] Ram Huggahalli, Ravi Iyer, and Scott Tetrick. Direct Cache Access for High Bandwidth Network I/O, 2005.
- [15] Intel R© 64 and IA-32 Architectures Optimization Reference Manual. Intel Corporation, May 2007.
- [17] Caol ́an McNamara. Controlling symbol ordering, April 2007.
- [18] Double Data Rate (DDR) SDRAM MT46V. Micron Technology, 2003. Rev. L 6/06 EN.
- [19] Jon “Hannibal” Stokes. Ars Technica RAM Guide, Part II: Asynchronous and Synchronous DRAM, 2004.
- [20] Static random access memory - Wikipedia, 2006.
这里我们忽略上溢(overflow)、下溢(underflow)、或是四舍五入(rounding)发生的可能算术影响 ↩︎
理论上在 1999 年修订版引入 C 语言的
restrict关键字应该解决这个问题。不过编译器还是不理解。原因主要是存在著太多不正确的程序码,其会误导编译器、并导致它产生不正确的目的码(object code) ↩︎测试是在一台 32 bit机器上执行的,因此
NPAD=15 代表每个列表元素使用一个 64 byte cache行 ↩︎气泡生动地描述在一个处理器的pipeline中执行的空洞,其会在执行必须等待资源的时候发生。关于更多细节,请读者参阅处理器设计的文献 ↩︎
对某些处理器而言,cache行并非指令的最小区块(atomic block)。Intel Core 2 前端会将 16 byte区块发给解码器。它们会被适当的对齐,因此没有任何被发出的区块能横跨cache行边界。对齐到cache行的开头仍有优点,因为它最佳化预取的正面影响 ↩︎
对于指令解码,处理器往往会使用比cache行还小的单元,在 x86 与 x86-64 的情况中为 16 byte ↩︎
很快就会有更好的方法! ↩︎
或是 non-instruction。这是推荐的未定义操作码 ↩︎
r4 与 r8 相同指的是值会被覆写的情况。 ↩︎
因为所有线程写入的数据都在同个cache行内。因此刚写入的cache行立刻就会因为其它线程也要对相同的cache行进行写入,而变为「I(无效)」状态。 ↩︎
通过名称标识的段是包含ELF文件中的代码和数据的原子单元。 ↩︎
这并不受 ISO C 标准保证,但 gcc 是这么做的。 ↩︎