

通常在mysql中存储树形结构的方案,是通过在子节点上存储父节点编号的方案来实现的。这种方案可以很直观的体现各个节点之间的关系,通常可以满足大多数需求。
但是当数据量变大和层级关系变深后,对于部分需求(例如,判断节点是否其他节点的子节点)这样的存储方式很难满足要求。这类需求实质上需要在内存中构建一棵树,通过遍历树来给出答案。如果还是使用parent_id这种存储模型,显然需要按照树的层级关系递归向下搜索。

通常在mysql中存储树形结构的方案,是通过在子节点上存储父节点编号的方案来实现的。这种方案可以很直观的体现各个节点之间的关系,通常可以满足大多数需求。
但是当数据量变大和层级关系变深后,对于部分需求(例如,判断节点是否其他节点的子节点)这样的存储方式很难满足要求。这类需求实质上需要在内存中构建一棵树,通过遍历树来给出答案。如果还是使用parent_id这种存储模型,显然需要按照树的层级关系递归向下搜索。
本篇是论文Presto: SQL on EveryThing的中文简单翻译

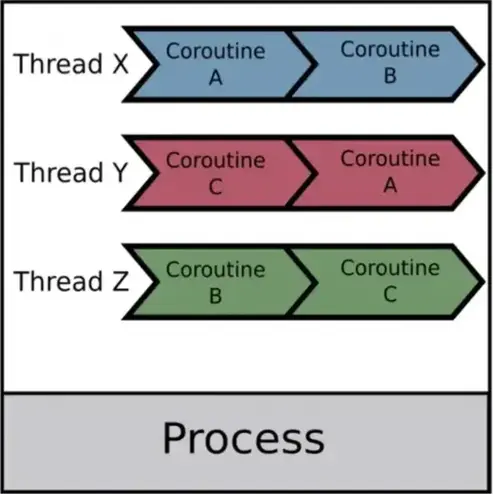
本文会介绍操作系统中的进程,线程和协程。
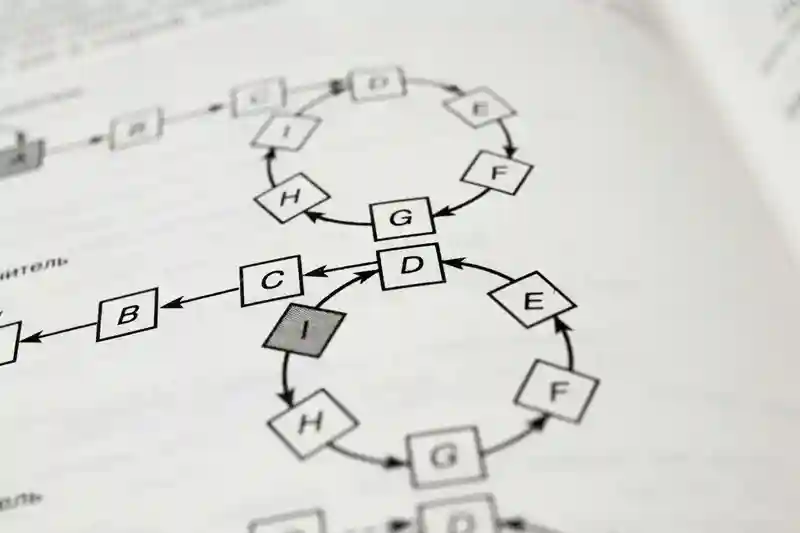
diff算法用于比较文本间的差异,通常用于版本控制系统,例如 git( $git diff)。

本文是 Doug Lea 的 “Scalable IO in Java” 读书笔记

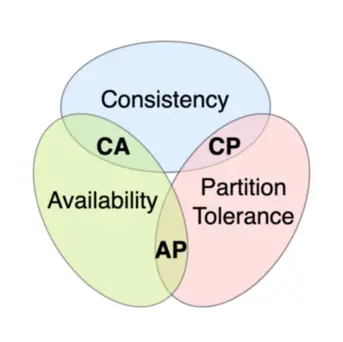
在前面的分布式系统理论中,我们了解到网络分区是大概率会发生的。分布式系统需要考虑在面临分区分区问题时,选择一致性还是高可用。本文将展开介绍分布式一致性模型(并行计算不涉及事务)。
CAP定理(CAP theorem),又被称作布鲁尔定理(Brewer’s theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
MD5 即Message-Digest Algorithm 5 (信息-摘要算法5)。MD5 使用little-endian(小端模式),输入任意不定长度信息,以 512-bit 进行分组,生成四个32-bit 数据,最后联合输出固定 128-bit 的信息摘要。
MD5 不是足够安全的。Hans Dobbertin在1996年找到了两个不同的512-bit 块,它们 在MD5 计算下产生相同的hash 值。至今还没有真正找到两个不同的消息,它们的MD5 的hash 值相等。