
Rsync 算法简介
你有没有遇到过这种情况:服务器上有两份代码,版本 A 和版本 B,你只想把 A 的改动同步到 B,但网络带宽只有几 Mbps,传输一个 24MB 的文件要等上好几分钟。
也许你会想到先在本地 diff,然后把 patch 发过去。没错,这是个思路。但你有没有想过:如果 A 和 B 都不在同一台机器上,diff 根本跑不起来怎么办?
这就是 rsync 要解决的问题。
你有没有遇到过这种情况:服务器上有两份代码,版本 A 和版本 B,你只想把 A 的改动同步到 B,但网络带宽只有几 Mbps,传输一个 24MB 的文件要等上好几分钟。
也许你会想到先在本地 diff,然后把 patch 发过去。没错,这是个思路。但你有没有想过:如果 A 和 B 都不在同一台机器上,diff 根本跑不起来怎么办?
这就是 rsync 要解决的问题。

正则表达式看似简单,底层却藏着五花八门的实现思路。本文将带你了解递归引擎、BBVM 虚拟机、Pike VM、Thompson DFA 和导数引擎的工作原理,帮助你在实际项目中做出明智的技术选型。

搬家后,Self-Host 服务无法通过公网 IPv4 访问,只能用 IPv6 + DDNS 方案。但家里路由器不支持精细的 IPv6 访问管理,开着防火墙会影响服务,关闭防火墙又等于裸奔。
最终通过三招解决了问题:反向代理隔离、登录增强、FRP 流量转发。

最近搬家,家里的 Self-Host 服务由于限制无法通过公网 IPv4 访问,就改用 IPv6 + DDNS 的方式提供公网域名访问。
切换完成后,立即收到云服务器上 Uptime Kuma 的告警,显示无法连接 IPv6 地址。排查发现 Docker 容器默认不支持 IPv6。
Colima 轻量、开源、免费 —— 在 Mac 上运行容器的最佳选择
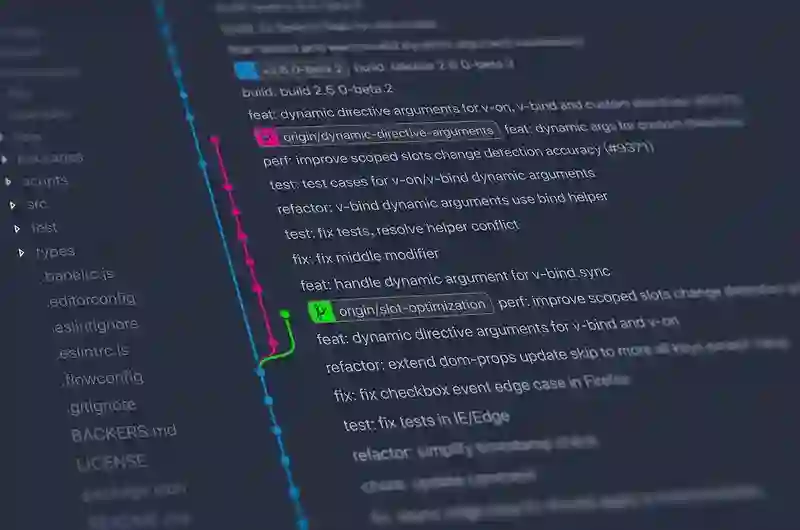
git worktree 命令支持管理同一个 git 仓库的多个工作区1,每个工作区可检出不同分支/提交。每个工作区都像一个“轻量级的独立仓库”,但它们共享底层对象库,减少磁盘占用并加速切换。
同一分支在同一时刻只能在一个 worktree 中被检出。如果想在多个 worktree 同时基于同一分支进行试验,需要使用不同分支名,或者使用--detach直接检出到某个提交。
注意,
--detach会产生分离式 HEAD,后续的修改会丢失,一般不推荐使用,除非是仅看用于查看代码。

最近完成了博客从 Hexo 到 Hugo 的迁移,这篇文章记录了迁移的完整历程,包括技术选型、具体实施步骤、遇到的问题以及解决方案。

本文主要介绍Calcite 中的AST转执行计划。关系代数最早由E. F. Codd在1970年的论文A Relational Model of Data for Large Shared Data Banks中提出, 是关系型数据库查询语言的基础, 也是查询优化技术的理论基础。 在Calcite内部, 会将SQL查询转化为一颗等价的关系算子树, 并在此基础上进行查询优化. 通用的关系代数理论可以参考之前的文章形式化关系查询语言, 接下来介绍在Calciate中的实现。
本文主要介绍Calcite 中的SQL Validator。Calcite 通过 SQL 校验器实现 SQL 绑定,SQL 校验器所需的 Catalog 信息,在深入理解 Apache Calcite Catalog 中已经做了详细的介绍。
SQL 绑定主要的作用是将 SQL 解析生成的 AST 和数据库的元数据进行绑定,从而生成具有语义的 AST。SQL 绑定会通过自底向上的方式遍历 AST,对抽象语法树中的节点进行绑定分析,绑定的过程中会将表、列等元数据附在语法树上,最后生成具有语义的语法树 Bounded AST。
Calcite 中的SQL Parser 使用JavaCC 实现。JavaCC 在前面的博客中有过介绍, 本文就不赘述了。本文主要介绍Parser。