

CPU分支预测对程序性能的影响
执行下面这段代码,你会发现排序的数组总是比未排序的数组计算快。
执行下面这段代码,你会发现排序的数组总是比未排序的数组计算快。
本文是CPU 流水线的简介。
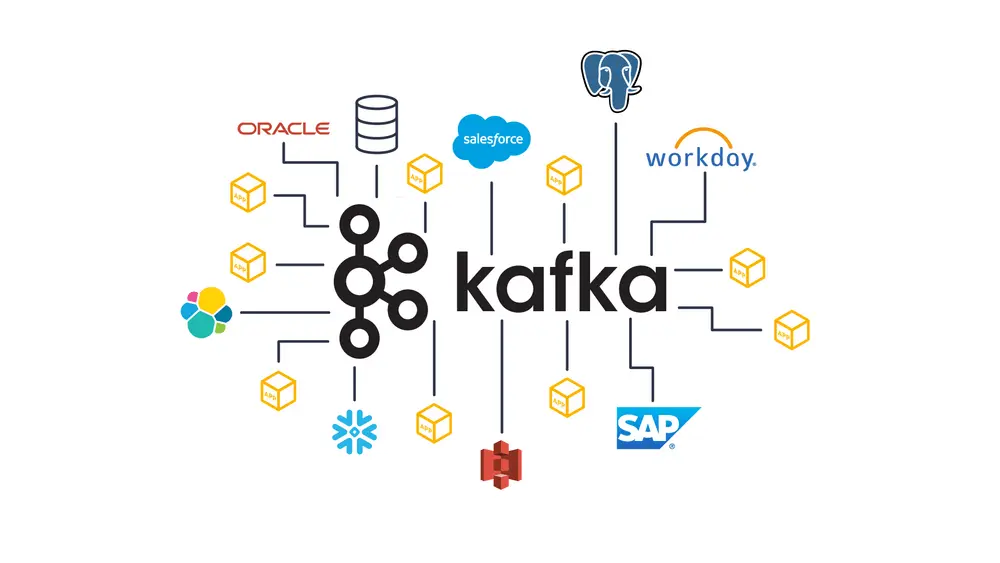
Apache Kafka 是一个开源的事件流平台,用户可以在其中创建 Kafka 主题作为数据传输单元,然后与生产者和消费者一起发布或订阅该主题。虽然大多数 Kafka 主题都在积极使用,但由于业务需求发生变化或主题本身是短暂的,因此不再需要一些主题。Kafka 本身没有自动检测未使用主题并删除它们的机制。这通常不是一个大问题,因为 Kafka 集群可以容纳相当多的主题,数百到数千个。但是,如果主题数量持续增长,最终会遇到一些瓶颈,并对整个 Kafka 集群产生破坏性影响。TopicGC服务的诞生就是为了解决这个确切的问题。事实证明,它通过删除~20%的主题来减轻Kafka的压力,并将Kafka的生产和消费性能提高了至少30%。

本文简单介绍了SIMD技术和SIMD在Java中的应用。SIMD(Single Instruction Multiple Data)即单指令流多数据流,是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。简单来说就是一个指令能够同时处理多个数据。

在前面我们简单介绍过分布式锁,本篇文章会介绍如果基于数据库(Mysql)实现分布式锁。基于Mysql实现锁的一般场景是对性能要求不高,且不希望因为分布式锁而引入新的组件的。

Trino 是一种旨在使用分布式查询高效查询大量数据的工具。通常用在数据仓储、数据分析、海量数据聚合和报表生成等任务上,这些任务通常被归类为联机分析处理(online analytical processing,OLAP)。
本文是学习Trino源码前的准备工作。在开始之前,先做好准备工作:

最近在做SQL方面的工作,主要是SQL语法解析和改写。因此打算记录下解析的技术&工具。
文本解析一般首推使用正则表达式。对于大多数的文本,正则都可以很好的解析。以ELK套件中的Logstash为例,其内置的Grok插件支持了120+种常用Pattern,可以很好的用于解析多种形式的文本。但是。正则不是文本解析的万能钥匙,由于正则表达式的自身实现约束,大多数正则表达式引擎不能较好的处理嵌套结构的数据。此外,对于脚本语言或编程语言,正则表达式也是无能为力。
举个例子,如果想替换SQL中的某个字段名,如果只是简单的使用正则替换,那么很可能会错误修改其他位置的文本。例如想修改下面SQL中的order_cnt别名时,就很有可能错误修改其他位置的order_cnt,要避免这类问题需要对正则添加很多断言和约束,由于实际场景中可能会对SQL的列名,表名,条件等各个位置进行改写,场景十分复杂。所以正则这种方式不能从根本上解决问题。由此,引出了接下来要介绍的技术–语法解析器(Parser)。
select
dt,
sum(order_cnt) as order_cnt
from(
select order_cnt
from order_info
where dt between xxx and xxx
)group by dt
LFU(Least Frequently Used)最近最少使用算法。它是基于“如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小”的思路。
举个例子,缓存空间大小为3:

Maven依赖传递是Maven的核心机制之一,它能够一定程度上简化Maven的依赖配置。